
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 웹서비스 기획
- 감정은 습관이다
- beautifulsoup
- SQL
- layer normalization
- 재현율
- 지도학습
- ifnull
- 정밀도
- 결정트리
- 강화학습
- CASE WHEN
- 데이터 프로젝트
- 평가 지표
- five lines challenge
- Batch Normalization
- 데이터 분석
- recall
- LAG
- sorted
- NVL
- nvl2
- 빠르게 실패하기
- NULLIF
- DecisionTree
- 오차 행렬
- 백엔드
- 비지도학습
- 데이터 전처리
- Normalization
- Today
- Total
Day to_day
[하루한끼_데이터] 문서 간 유사도 검사를 통한 추천 시스템 만들기 #1 본문
유사도 검사를 통해 유저가 좋아요를 누른 레시피와 가장 유사도가 높은 레시피를 추천해보는 건 어떻냐는 피드백을 받았다. 일단! 나는 문서 간의 유사도 검사라는 말을 처음 들었고, 어떤 원리로 작동되는지도 잘 몰라서 감이 잘 잡히지 않았다.
그래서 이번 기회에 공부하면서 사용도 해보고싶어서 바로 주말 동안 호다다닥 시작했다.
조금 급하게 학습한거라 자세한 내용들이 틀릴 수도 있겠지만 일단은 이해한 바를 써보고, 추후에 전문서적을 사서 더 자세히 공부하고 정확하게 알아가면 살을 붙이면서 완성도를 높이려 한다.
일단 스따뜨~!
전체 코드는 "[NLP] 문서 군집화(Clustering)와 문서 간 유사도(Similarity) 측정하기"를 참고하여 작성되었습니다.
전에 데이터에 대해 소개했듯이 나는 레시피의 '재료'와 '조리과정'의 텍스트가 있다. 먼저 '재료'가 비슷한 레시피를 찾는 것을 목표로 진행해보자.
0. 전처리
전처리 과정을 한번 더 했다.
굳이 한번 더 했던 이유는 그전에 했던 전처리는 서비스에 바로 보여주어야 하는 데이터로서 '/n', '/ml', 'g' 등 단위에 대한 텍스트가 모두 있다. 그리고 다 필요한 정보이기 때문에 삭제할 수가 없었다.
하지만 유사도 검사의 경우 작동원리는 간단하게 설명하면 전체 문서에서 자주 나오는 단어들이 다른 문서에선 자주 나오지 않는 경우 높은 가중치를 둔다. 즉 'a', 'the', 'be 동사' 같은 경우가 그 문서를 대표할만한 단어가 되지 않게 하는 것이다.
재료의 단위나 괄호 등을 모두 지워주고 이전에 했던 방식(정규표현식)으로 쉽게 끝마칠 수 있었다.
1. 토큰화 시키기
문서를 토큰화 시킨다는 것은 뭘까?
토큰화 한다는 것은 쉽게 말해서 단어 단어로 문장을 분리해 놓는 거라고 생각하면 쉽다. 단어 단위 외에도 단어 구, 의미를 갖는 문자열 등으로 토큰화 시킬 수도 있다.
그러면 토큰화시키는 것은 예를 들면 문장의 띄어쓰기를 이용해서 분리할 수가 있다.
더 구체적으로 생각해보자면 구두점(마침표(.), 컴마(,), 물음표(?), 세미콜론(;), 느낌표(!) 등과 같은 기호)을 제외시키고 띄어쓰기 기준으로 잘라내면 쉽게 단어 단어로 끊어낼 수 있을 것이다.
그래서 먼저 구두점을 딕셔너리 형태로 만들어 모든 구두점을 없앨 것이다.
from sklearn.feature_extraction.text import TfidfVectorizer
from nltk.stem import WordNetLemmatizer
import nltk
import string
#string.puncutation에 문자열의 모든 구두점이 들어있음 (!"#$%&'()*+, -./:;<=>?@[\]^_`{|}~)
#ord('문자열') => 문자열의 ASCII 코드를 반환
#dict(key, value) 형태로 모든 구두점의 각 ASCII 코드를 key 값으로 넣어주기
remove_punct_dict = dict((ord(punct), None) for punct in string.punctuation)
lemmar = WordNetLemmatizer()
print(remove_punct_dict) # 모든 구두점들을 아스키코드로 변환한 것위의 코드를 실행시켜 보자면,
아래와 같이 구두점이 아스키코드로 변환되고 모두 None을 넣어 딕셔너리를 만든 것을 알 수 있다.

그렇담 이제 각 단어의 핵심 의미를 찾는 작업이 필요할 것이다. 예를 들어 'had', 'have', 'has'는 모두 같은 의미의 'have'로 대표를 두어도 상관없을 것이다. 그러면 이제 '어간 추출'과 '표제어 추출'의 개념에 대해 먼저 알아야 한다.
어간 추출(Stemming)과 표제어 추출(Lemmatization)
정규화 기법 중 코퍼스(corpus)에 있는 단어의 개수를 줄일 수 있는 기법이다. (코퍼스 == 말뭉치)
두 작업의 의미는 눈을 봤을 땐 서로 다른 단어들이지만, 하나의 단어로 일반화시킬 수 있다면 하나의 단어로 일반화시켜서 문서 내의 단어 수를 줄이는 목적을 갖고 있다.
자연어 처리에서 전처리, 더 정확히는 정규화의 지향점은 언제나 갖고 있는 코퍼스로부터 복잡성을 줄이는 일이다.
표제어 추출 Lemmatization
표제어 추출은 단어들이 다른 형태를 가지더라도, 그 뿌리 단어를 찾아가서 단어의 개수를 줄일 수 있는지 판단한다.
예를 들어 am, are, is는 서로 다른 스펠링이지만 그 뿌리 단어는 be라고 볼 수 있다. 그렇다면 이 단어들의 표제어는 be라고 한다.
표제어 추출을 하는 가장 섬세한 방법은 단어의 형태학적 파싱을 먼저 진행하는 것이다.
형태소의 종류는 어간(stem)과 접사(affix)가 존재한다.
- 어간(stem) : 단어의 의미를 담고 있는 단어의 핵심 부분
- 접사(affix) : 단어에 추가적인 의미를 주는 부분
NLTK에서는 표제어 추출을 위한 도구인 WordNetLemmatizer를 지원한다.
<예제>
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
words = ['policy', 'doing', 'organization', 'have', 'going', 'love', 'lives', 'fly', 'dies', 'watched', 'has', 'starting']
print('표제어 추출 전 :',words)
print('표제어 추출 후 :',[lemmatizer.lemmatize(word) for word in words])
<출력 결과>
표제어 추출 전 : ['policy', 'doing', 'organization', 'have', 'going', 'love', 'lives', 'fly', 'dies', 'watched', 'has', 'starting']
표제어 추출 후 : ['policy', 'doing', 'organization', 'have', 'going', 'love', 'life', 'fly', 'dy', 'watched', 'ha', 'starting']
- 표제어 추출은 단어의 형태가 적절히 보존되는 양상을 보이는 특징이 있다.
- 하지만 그럼에도 위의 결과에서는 dy나 ha와 같이 의미를 알 수 없는 적절하지 못한 단어를 출력한다.
- 이는 표제어 추출기가 본래 단어의 품사 정보를 알아야만 정확한 결과를 얻을 수 있기 때문이다.
lemmatizer.lemmatize('dies', 'v')
# 'die'
- 이런 식으로 단어의 품사를 알려주면 표제어 추출기는 품사의 정보를 보존하면서 정확한 Lemma를 출력하게 된다.
어간 추출(Stemming)
어간을 추출하는 작업은 형태학적 분석을 단순화한 버전이라고 볼 수 있다.
정해진 규칙에 의해서 어미를 자르는 어림짐작의 작업으로 볼 수도 있으며, 이 작업은 섬세한 작업이 아니기 때문에 결과 단어는 사전에 존재하지 않는 단어일 수도 있다.
어간 추출 알고리즘 중 하나인 포터 알고리즘(Porter Algorithm)을 이용하여 예제 문자열을 넣는다고 해보자
<예제>
from nltk.stem import PorterStemmer
from nltk.tokenize import word_tokenize
stemmer = PorterStemmer()
sentence = "This was not the map we found in Billy Bones's chest, but an accurate copy, complete in all things--names and heights and soundings--with the single exception of the red crosses and the written notes."
tokenized_sentence = word_tokenize(sentence)
print('어간 추출 전 :', tokenized_sentence)
print('어간 추출 후 :',[stemmer.stem(word) for word in tokenized_sentence])
<실행 결과>
어간 추출 전 : ['This', 'was', 'not', 'the', 'map', 'we', 'found', 'in', 'Billy', 'Bones', "'s", 'chest', ',', 'but', 'an', 'accurate', 'copy', ',', 'complete', 'in', 'all', 'things', '--', 'names', 'and', 'heights', 'and', 'soundings', '--', 'with', 'the', 'single', 'exception', 'of', 'the', 'red', 'crosses', 'and', 'the', 'written', 'notes', '.']
어간 추출 후 : ['thi', 'wa', 'not', 'the', 'map', 'we', 'found', 'in', 'billi', 'bone', "'s", 'chest', ',', 'but', 'an', 'accur', 'copi', ',', 'complet', 'in', 'all', 'thing', '--', 'name', 'and', 'height', 'and', 'sound', '--', 'with', 'the', 'singl', 'except', 'of', 'the', 'red', 'cross', 'and', 'the', 'written', 'note', '.']
- 어간 추출 속도는 표제어 추출보다 일반적으로 빠른데, 포터 어간 추출기는 정밀하게 설계되어 정확도가 높으므로 영어 자연어 처리에서 어간 추출을 하고자 한다면 가장 준수한 선택이다.
어간 추출 알고리즘 비교
포터 알고리즘 vs 랭커스터 스태머 알고 리즘
<예제>
from nltk.stem import PorterStemmer
from nltk.stem import LancasterStemmer
porter_stemmer = PorterStemmer()
lancaster_stemmer = LancasterStemmer()
words = ['policy', 'doing', 'organization', 'have', 'going', 'love', 'lives', 'fly', 'dies', 'watched', 'has', 'starting']
print('어간 추출 전 :', words)
print('포터 스테머의 어간 추출 후:',[porter_stemmer.stem(w) for w in words])
print('랭커스터 스테머의 어간 추출 후:',[lancaster_stemmer.stem(w) for w in words])
어간 추출 전 : ['policy', 'doing', 'organization', 'have', 'going', 'love', 'lives', 'fly', 'dies', 'watched', 'has', 'starting']
포터 스테머의 어간 추출 후: ['polici', 'do', 'organ', 'have', 'go', 'love', 'live', 'fli', 'die', 'watch', 'ha', 'start']
랭커스터 스테머의 어간 추출 후: ['policy', 'doing', 'org', 'hav', 'going', 'lov', 'liv', 'fly', 'die', 'watch', 'has', 'start']
- 두 어간 추출 알고리즘은 서로 다른 알고리즘을 사용하기 때문에 결과가 다르게 나타난다.
- 사용하고자 하는 코퍼스에 stemmer를 적용해보고 어떤 stemmer가 해당 코퍼스에 적합한지를 판단 후 사용하기
- 또한 어간 추출을 하고 나서 일반화가 지나치게 되거나 덜 되거나 하는 경우가 있는데 잘 살펴봐야 한다.
- ex ) organization → organ
- 둘은 완전히 다른 단어임에도 규칙에 따라 추출하였다. 이것이 과도하게 일반화가 된 것.
stemming vs Lemmatization
Stemming
am → am
the going → the go
having → hav
Lemmatization
am → be
the going → the going
having → have
이제 핵심은 토큰화한 각 단어들의 원형을 뽑아내는 것이다.
이 코드는 아래와 같다.
# 토큰화한 각 단어들의 원형들을 리스트로 담아서 반환
def LemTokens(tokens):
return [lemmar.lemmatize(token) for token in tokens]
# 텍스트를 input으로 넣어서 토큰화시키고 토근화된 단어들의 원형들을 리스트로 담아 반환
def LemNormalize(text):
# .translate 인자에 구두점 dict 넣어주어서 구두점 삭제해준 상태로 토큰화 시키기
return LemTokens(nltk.word_tokenize(text.lower().translate(remove_punct_dict)))아까 생성해 둔 {구두점, None} 형태의 딕셔너리를 써서 구두점은 모두 none 값으로 만들어 주고, 그 상태로 토큰화 하고 LemTokens 함수에 넣어 원형들을 리스트로 반환한다.
* 이때 사용한 lemmar.lemmatize는 표제어 추출을 통해서 단어의 원형들을 반환하는 함수이다.
2. 벡터화 하기
벡터화하는 과정은 앞서 잠깐 설명했듯이 문서를 대표하는 특징 벡터를 뽑아내는 것이라 생각하면 된다.
그러면 그 계산 과정을 어떻게 만들까?
중요한 개념인 TF-IDF(Term Frequency-Inverse Document Frequency)에 대해 알아봐야 한다.
TF-IDF(Term Frequency-Inverse Documnet Frequency)
각 단어에 대한 중요도를 계산할 수 있는 TF-IDF 가중치
TF-IDF를 사용하면 많은 정보를 고려하여 문서들을 비교할 수 있다.
TF-IDF는 TF와 IDF를 곱한 값을 의미한다.
tf(d, t) : 특정 문서 d에서의 특정 단어 t의 등장 횟수
df(f) : 특정 단어 t가 등장한 문서의 수
=> 한 단어가 특정 문서에 100번 반복된다 할지라도, 그 단어는 문서 1개에 등장한 것이므로, 그 단어의 df(f)는 1이 되는 것
idf(d, t) : df(t)에 반비례하는 수
- Df (Document Frequency)는 문서 빈도. 특정 단어가 몇 개의 문서(문장)에서 등장하는지를 수치화한 것. 그것의 역수가 idf다. 보통 그냥 역수를 취하기보다는 아래처럼 수식화한다.
- 역수의 개념을 사용하는 이유는, 적은 문서(문장)에 등장할수록 가중치를 크게 주고 반대로 많은 문서(문장)에 등장할수록 가중치를 줄임으로써 여러 문장에 의미 없이 사용되는 단어의 가중치를 줄이기 위함이다
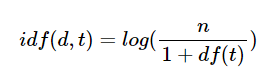
- d : 문서
- t : 단어
- n : 문서의 총 개수
- df(t) : 특정 단어 t가 등장한 문서의 수
TF-IDF는 모든 문서에서 자주 등장하는 단어는 중요도가 낮다고 판단하며, 특정 문서에서만 자주 등장하는 단어는 중요도가 높다고 판단한다.
TF-IDF 값이 낮으면 중요도가 낮은 것이며, TF-IDF 값이 크면 중요도가 큰 것이다. 즉, the나 a와 같이 불용어의 경우에는 모든 문서에 자주 등장하기 마련이기 때문에 자연스럽게 불용어의 TF-IDF의 값은 다른 단어의 TF-IDF에 비해서 낮아지게 된다.
TF-IDF에 대해 더 자세히 알고 파이썬으로 직접 구현하고 싶다면 여기서 확인할 수 있다.
그러면 이 TF-IDF 벡터화를 진행하는 것은 그리 어렵진 않다. 이미 scikit-learn에서 제공하는 'TfidfVectorizer'로 몇 가지 값을 조절하여 벡터화를 시킬 수 있다.
# Tf-idf 벡터화시키면서 customized해준 토큰화+어근 추출 방식 tokenizer 인자에 넣어주기
# 벡터화 시킬 Tf-idf 도구 옵션 추가해서 구축
# 1,2gram 적용, 빈도수 0.05이하, 0.85이상의 빈도수 단어들 제거
tfidf_vect = TfidfVectorizer(tokenizer=LemNormalize,
stop_words='english', ngram_range=(1,2),
min_df=0.05, max_df=0.85)
# fit_transform으로 위에서 구축한 도구로 텍스트 벡터화
ftr_vect = tfidf_vect.fit_transform(df['ingredients_list'])
TfidfVectorizer() 인수
- stop_words : 문자열 {’english’}, 리스트 또는 None(디폴트)
- token_pattern : string (토큰 정의용 정규 표현식)
- tokenizer : 함수 또는 None(디폴트)=> 토큰 생성 함수
- ngram_range : (min_n, max_n) 튜플=> n-그램 범위
- max_df : 정수 또는 [0.0, 1.0] 사이의 실수. 디폴트 1=> 단어장에 포함되기 위한 최대 빈도
- min_df : 정수 또는 [0.0, 1.0] 사이의 실수. 디폴트 1=> 단어장에 포함되기 위한 최소 빈도
Stop words
문서에서 단어장을 생성할 때 무시할 수 있는 단어를 말한다. 보통 영어의 관사나 접속사, 한국어의 조사 등이 여기에 해당한다.
n그램
N 그램은 단어장 생성에 사용할 토큰의 크기를 결정. 모노그램은 토큰 하나만 단어로 사용하며, 바이그램은 두 개의 연결된 토큰을 하나의 단어로 사용
<예제>
vect = CountVectorizer(ngram_range=(2, 2)).fit(corpus)
vect.vocabulary_
<출력 결과>
{'this is': 12,
'is the': 2,
'the first': 7,
'first document': 1,
'the second': 9,
'second second': 6,
'second document': 5,
'and the': 0,
'the third': 10,
'third one': 11,
'is this': 3,
'this the': 13,
'the last': 8,
'last document': 4}
<예제 2>
vect = CountVectorizer(ngram_range=(1, 2), token_pattern="t\\w+").fit(corpus)
vect.vocabulary_
<출력 결과>
{'this': 3, 'the': 0, 'this the': 4, 'third': 2, 'the third': 1}
min_df & max_df
max_df
max_df는 너무 자주 나타나는 단어를 지우기 위해 사용된다. 이런 단어를 ‘코퍼스 특이적 불용어’라고 부른다.
max_df의 기본값은 1.0으로, 이 값은 모든 문서에서 출현한 단어에 대해서 무시하라는 의미. 즉 기본 값은 어떤 단어도 무시하지 말라는 말이다.
- max_df = 0.50
- : 문서에서 50% 이상 나온 단어를 무시한다.
- max_df = 25
- : 25번 이상 나온 단어를 무시한다.
min_df
기본값은 1이며, 이것은 1번 이하로 나온 단어를 무시하라는 말로 어떤 단어도 무시하지 말라는 의미이다.
- min_df = 0.01
- : 1% 이하로 나온 문서를 무시하라는 의미이다.
- min_df = 5
- : 5개 이하로 나온 단어에 대해서 무시하라는 의미
다음은 군집화와 코사인 유사도를 이용하여 결론을 도출해 보겠다.
글이 너무 길어질 것 같아서... 이만
Ref
'Project' 카테고리의 다른 글
| [체어코치_기획] 새로운 프로젝트 시작! (0) | 2022.12.22 |
|---|---|
| [하루한끼_데이터] 문서 간 유사도 검사를 통한 추천 시스템 만들기 #2 (1) | 2022.12.21 |
| [하루한끼_데이터] 이미지 url 크롤링 (0) | 2022.11.09 |
| [하루한끼_데이터] 데이터 전처리 2 : 정규표현식 (0) | 2022.11.07 |
| [하루한끼_데이터] 데이터 전처리 1 (0) | 2022.11.02 |



