
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- five lines challenge
- 데이터 분석
- LAG
- Normalization
- nvl2
- 비지도학습
- 강화학습
- 평가 지표
- 재현율
- Batch Normalization
- NVL
- 정밀도
- DecisionTree
- SQL
- layer normalization
- 결정트리
- sorted
- 백엔드
- ifnull
- 데이터 프로젝트
- 빠르게 실패하기
- 지도학습
- CASE WHEN
- 오차 행렬
- NULLIF
- 데이터 전처리
- recall
- beautifulsoup
- 웹서비스 기획
- 감정은 습관이다
- Today
- Total
Day to_day
교차 검증(Cross Validation)이란? 교차 검증의 종류 및 사용법 본문
❗본 포스팅은 권철민 선생님의 '파이썬 머신러닝 완벽가이드' 강의와 '파이썬 라이브러리를 활용한 머신러닝' 서적을 기반으로 개인적인 정리 목적 하에 재구성하여 작성된 글입니다.
포스팅 개요
학습, 검증, 테스트 데이터 셋을 나누고 그 용도에 대해서는 이해를 했다.
그런데 cross validation을 배우면서 그 개념과 목적이 조금 헷갈려서 이번 포스팅에서는 cross validation을 실습 코드로 기본 사용법을 익히고, K-Fold cross validation 뿐만 아니라 다른 교차 검증 종류에 대해서도 정리하고자 한다.
교차 검증의 개념
교차 검증은 일반화 성능을 재기 위해 사용하는 훈련 데이터셋과 테스트 데이터 셋으로 한번 나누는 것보다 더 안정적이고 뛰어난 통계적 평가 방법이다.
다시 말하면, 학습 데이터를 학습(train dataset)과 검증(validation dataset)데이터로 나눠서 학습 데이터를 가지고 모델의 성능을 1차로 먼저 평가하는 검증 데이터를 만든다. 그다음 테스트(test dataset)는 마지막으로 최종 그 모델의 성능을 확인할 때 사용되는 것이다.
한 가지 내가 헷갈렸던 것은 '교차 검증은 새로운 데이터에 적용할 모델을 만드는 방법이 아니라 목적은 단지 주어진 데이터셋에 학습된 알고리즘이 얼마나 일반화되었는가'를 확인하는 것이다.
대표적인 교차 검증 방법 - K Fold 교차 검증
대표적인 교차 검증 방법으로 K-Fold 교차 검증이 있다.
K개의 폴드 세트를 만들어서 아래의 그림과 같이 K번의 학습과 검증을 마치고, 각 검증 평가의 평균을 낸 것인 최종 검증 평가이다.

K-Fold 교차 검증 종류
K-Fold 교차 검증은 두 가지 종류가 있다.
일반적으로 1) 순서대로 나열된 레이블에 적용한 교차 검증이 있고, 데이터가 불균형할 때 2) 클래스의 분포 비율에 맞게 폴드를 만드는 교차 검증이 있다.
일반 K Fold
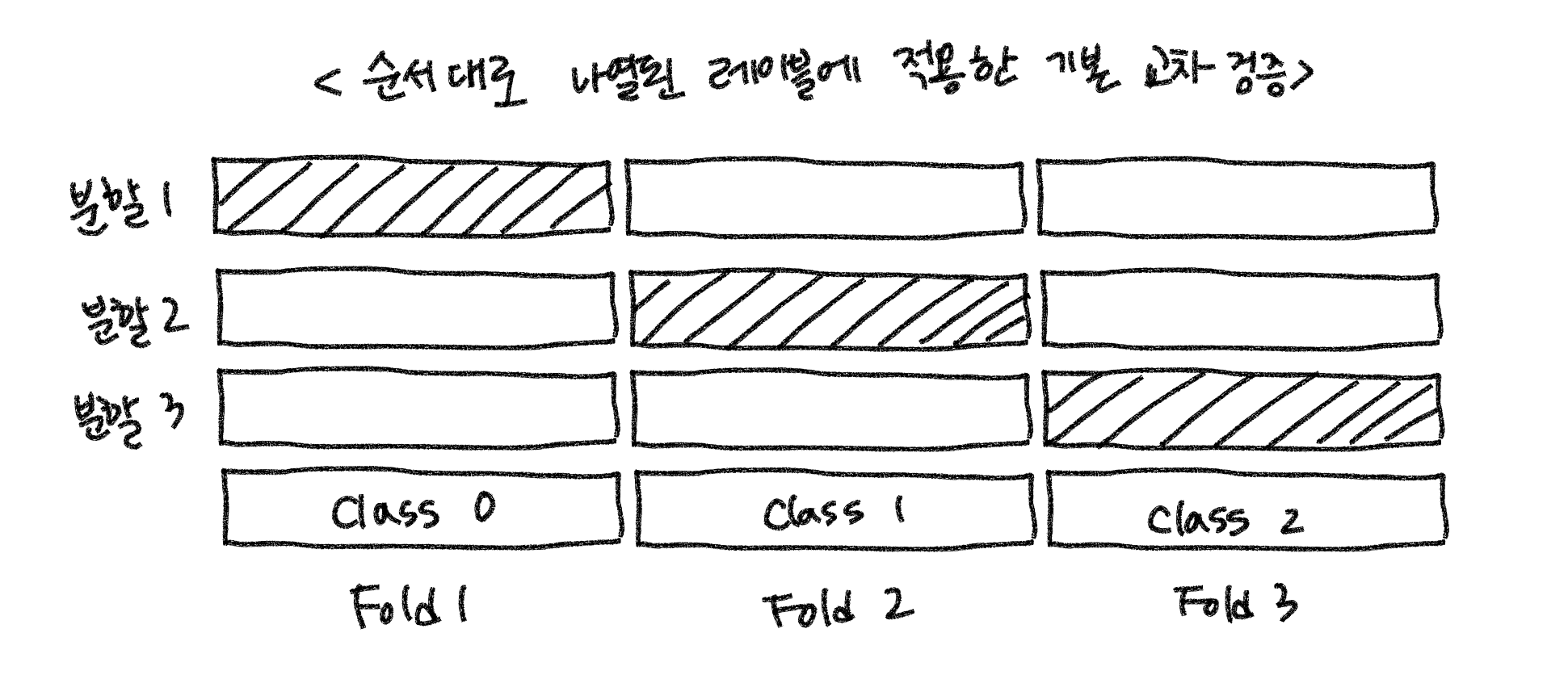
< 분할 시 섞지 않고 폴드를 생성했을 경우 결과 >

Stratified K Fold

< Stratified K-Fold를 사용하여 클래스 비율에 맞게 폴드 생성 결과 >

교차 검증 사용하기! (feat. cross_val_score)
< 교차 검증의 과정 요약 >
- 폴드 세트 설정
- For 루프에서 반복적으로 학습/검증 데이터 추출 및 학습과 예측 수행
- 폴드 세트별로 예측 성능을 평균하여 최종 성능 평가
→ cross_val_score() 함수로 폴드 세트 추출, 학습/예측, 평가를 한 번에 수행 가능하다!
< cross_val_score( ) 파라미터 >
estimator : 어떤 알고리즘 쓸지
X : 학습 데이터
y : 라벨(타겟) 데이터
scoring : 학습의 성능 지표는 뭘로 할 것인가 (ex accuracy, precision, recall…)
cv : 몇 개의 폴드로 나눌 것인가
[실습 코드]
아래의 코드에서는 scoring을 따로 지정해주지 않아, estimator(예제에서는 LinearRegression)로 사용한 모델의 디폴트 scoring을 따르게 된다.
# estimator: lr_clf, X: iris_data, y: target, cv: 5
score = cross_val_score(lr_clf, iris_data, target, cv=5) # fold 5개
print("교차 검증 점수: ", score)
print("평균 교차 검증 점수: {0:.4f}".format(round(np.mean(score), 4)))
교차 검증의 장단점
▶ 장점
- 만약 모델의 일반화를 평가하기 위해 test data로 정확도 평가로 사용하는데 운이 안 좋아서 분류하기 어려운 샘플들이 모두 테스트 데이터로 들어간다면 그 모델의 정확도는 현저히 떨어질 것이다.
- 위의 경우를 막기 위해 교차 검증에서는 검증 세트(validation data)에 각 샘플이 정확하게 한번씩 들어간다. 교차 검증 방법을 사용하면 적어도 모든 샘플 데이터는 폴드 중 하나에 속하고, 한 번씩 테스트 데이터 세트가 되기 때문에 일반화를 평가하기 좋다.
- 각 폴드별로 정확도의 평균을 구하는 것이기 때문에 결국 테스트 셋에 있는 모든 샘플에 대해 모델이 잘 일반화되어야 한다.
▶ 단점
- 한번의 검증만 거쳐서 평가하는 것이 아니라 여러 번 검증을 하며 전체 평균을 내는 것이기 때문에 연산 비용이 늘어난다는 단점이 있다.
다른 종류의 교차 검증
LOOCV (Leave-one-out Cross-validation)
폴드 하나에 샘플 하나만 들어있는 k-겹 교차 검증이다.
총 N(샘플 수)번의 모델을 만들고, 각 모델을 만들 때 전체 train dataset 중에 하나의 데이터만 validation dataset으로 두고, 나머지는 모두 train dataset으로 사용한다. 그 과정을 샘플 수만큼 진행하고, 정확도를 평균 낸다.
이 방법은 데이터 셋이 클 때는 시간이 매우 오래 걸리지만, 작은 데이터 셋에서는 더 좋은 결과를 만들어낸다.
[실습코드]
from sklearn.model_selection import LeaveOneOut
# loo 선언
loo = LeaveOneOut()
scores = cross_val_score(lr_clf, iris_data, target, cv=loo)
print('교차 검증 분할 횟수:', len(scores))
print('교차 검증 분할 scores:', scores)
print("평균 정확도 : {0:.2f}".format(scores.mean()))
임의 분할 교차 검증 (Shuffle Split)
임의의 분할 교차 검증에서는 train_size 만큼의 포인트로 훈련 세트를 만들고, test_size만큼의 (train dataset과 중첩되지 않는) 포인트로 테스트 세트를 만들도록 분할한다.
이 분할은 n_splits 횟수만큼 반복된다.
< 임의 분할 교차 검증의 특징 >
- 반복 횟수를 훈련 세트나 테스트 세트의 크기와 독립적으로 조절해야할 때 유용
- train_size와 test_size의 합을 전체와 다르게 함으로써 전체 데이터의 일부만 사용 가능
- 대규모 데이터를 작업할 때 부분 샘플링 할 수 있다는 장점

위의 예시의 경우, train_size = 3, test_size = 2, n_split = 4로 설정되었다.
그래서 train dataset으로 각 분할마다 3개씩, test dataset의 경우는 2개씩 랜덤으로 골랬다. 또한 선택되지 않은 데이터는 각 분할마다 3개씩 있다.
[실습코드]
from sklearn.model_selection import ShuffleSplit
# 데이터셋의 50%를 train 세트, 50%를 test세트로 10번 분할
shuffle_split = ShuffleSplit(test_size=.5, train_size=.5, n_splits=10)
scores = cross_val_score(lr_clf, iris_data, target, cv=shuffle_split)
print("교차 검증 점수:\n", scores)
그룹별 교차 검증 (Group K-Fold)
데이터 안에 매우 연관된 그룹이 있을 때 그룹별 교차 검증을 사용한다.
예를 들어 한 사람의 여러 얼굴 표정 데이터를 모았고, 또 다른 사람의 여러 얼굴 표정을 모은 뒤 어떤 표정인지 맞추는 모델이 있다고 하자. 이 경우 같은 사람의 표정이 train, test 데이터 둘에 들어가 있을 수 있고, 그렇게 되면 같은 사람의 얼굴이기 때문에(표정은 달라도) 모델이 더 쉽게 맞출 수도 있다.
즉 클래스는 다르지만, 매우 연관된 데이터 (한 사람의 데이터, 한사람의 목소리, 한사람의 표정, 한사람의 의료기록..)에 대해서 그룹을 먼저 만들고 같은 그룹의 데이터가 훈련과 테스트 데이터 모두에 들어가게 하지 않는 것이 중요하다! (새로운 그룹으로 테스트를 하도록 하기 위함!)

[실습 코드]
from sklearn.model_selection import GroupKFold
from sklearn.datasets import make_blobs
gkf = GroupKFold(n_splits=3)
# 인위적인 데이터 생성
X, y = make_blobs(n_samples=12, random_state=0)
# 처음 세 개의 샘플은 같은 그룹에 속함
groups= [0,0,0,1,1,1,1,2,2,3,3,3]
scores = cross_val_score(lr_clf, X, y, groups=groups, cv=gkf)
print("교차 검증 점수:\n", scores)
반복 교차 검증 (Repeated Stratified K-Fold)
cross_val_score 함수의 cv 매개변수에 전달하여 교차 검증을 반복할 수 있다.
반복할 때마다 서로 다른 분할이 생성된다는 것이 특징이다.
[실습 코드]
from sklearn.model_selection import RepeatedStratifiedKFold
rskf = RepeatedStratifiedKFold(random_state=42)
scores = cross_val_score(lr_clf, iris_data, target, cv=rskf)
print("교차 검증 점수:\n", scores)
print("교차 검증 평균 점수: {:.3f}".format(scores.mean()))'Machine Learning > 머신러닝 기초' 카테고리의 다른 글
| [데이터 전처리] 데이터 인코딩의 종류와 활용 방법~! (0) | 2023.03.31 |
|---|---|
| [데이터 전처리] Feature Engineering의 종류와 구현하기! (이상치제거, 결측치 처리, log 변환) (0) | 2023.03.22 |
| Grid Search CV의 개념 및 장단점 (1) | 2023.02.24 |
| [모델 평가] 정밀도-재현율 곡선과 f1 score, ROC, AUC 이해하기 (0) | 2023.02.13 |
| [모델 평가] 이진 분류에서 평가 지표 개념 바로 알기 (오차행렬, 정밀도, 재현율) (1) | 2023.02.06 |



