
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- NVL
- CASE WHEN
- 웹서비스 기획
- 데이터 프로젝트
- 백엔드
- Batch Normalization
- 비지도학습
- recall
- layer normalization
- 지도학습
- 빠르게 실패하기
- SQL
- 감정은 습관이다
- DecisionTree
- 강화학습
- five lines challenge
- Normalization
- 오차 행렬
- nvl2
- ifnull
- LAG
- sorted
- 데이터 전처리
- 재현율
- 데이터 분석
- NULLIF
- 평가 지표
- 결정트리
- 정밀도
- beautifulsoup
- Today
- Total
Day to_day
[논문 리뷰] Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena 본문
이 논문의 핵심!
- 이 논문에서 해결하고자 하는 문제는 LLM 기반 채팅 어시스턴트를 평가할 때 기존 벤치마크가 이들의 광범위한 기능과 인간의 선호도를 충분히 반영하지 못한다는 것이다.
- 그래서 두 가지 벤치 마크를 도입한 것과 LLM을 평가자로 사용하는 방법을 제안한다.
- 또한 LLM-as-a-judge(LLM을 평가자로 사용)의 사용과 한계를 실험을 통해 보여주며, 한계를 완화하기 위한 해결 방안도 제안한다.
- 그 결과 GPT-4와 같은 강력한 LLM 평가자가 통제된 환경과 크라우드소싱된 인간 선호도 모두에서 80% 이상의 일치율을 달성하여 인간 간의 일치율과 동일한 수준을 달성할 수 있었고, 이는 인간 평가자를 통해 소요되는 높은 비용을 대체 가능할 수 있음을 시사했다.
Intro
LLM 기반의 chatbot이 human 피드백을 통한 강화학습을 활용해서 점점 더 좋은 성능을 보이는 것은 자명한 사실이다. 이는 human align이 이루어지면서 기존의 채팅 모델보다 훨씬 더 사용자에게 선호되는 결과가 나왔지만 이러한 향상이 기존 LLM 벤치마크 점수에서는 향상으로 이어지진 않는다.
MMLU와 HELM 같은 벤치마크는 이러한 사용자 선호에 맞는 모델과 기본 모델 간의 차이를 효과적으로 구분하지 못하고 이 현상은 챗봇의 유용성에 대한 사용자 인식과 기존 벤치마크에서 사용하는 평가 기준 간에 갭이 있다는 것을 의미한다.
기존 평가의 핵심 문제
기존 평가는 제한된 작업(객관식 지식, 정보 검색 질문)에 대해서만 측정하고 인간 선호도는 크게 고려하지 않은 평가 방식 때문에 문제가 발생한다. 그래서 본 논문에서는 인간 선호도를 고려하여 LLM을 평가할 수 있는 강력하고 확장 가능한 자동화된 평가 방법의 필요하다고 주장한다.
MT-bench와 Chatbot Arena
기존 벤치마크는 세 가지 범주로 나눌 수 있다.
핵심 지식 벤치마크
MMLU, HellaSwag, ARC, WinoGrande, HumanEval, GSM-8K, AGIEval 등은 사전 학습된 LLM의 핵심 능력을 zero shot 및 few shot 벤치마크 세트를 사용하여 평가하는 방식이다. 이 벤치마크의 특징은 LLM이 자동으로 검증할 수 있는 짧고 구체적인 답변을 생성하도록 요구하는 경우가 많다.
명령 수행 벤치마크
Flan, Self-instruct, NaturalInstructions, Super-NaturalInstructions 같은 벤치마크는 좀 더 개방형 질문과 다양한 작업을 포함한다.
대화형 벤치마크
CoQA, MMDialog, OpenAssistant 같은 벤치마크는 우리가 의도하는 사용 사례와 가장 가까우나 이들의 질문의 다양성과 복잡성은 최신 챗봇의 능력을 충분히 시험하지 못하는 경우가 많다.
이 논문에서는 새로운 벤치마크로 MT-bench와 Chatbot Arena를 제안한다.
MT-bench
80개의 고품질 다중 턴 질문으로 구성되었으며 다중 턴 대화와 명령 수행 능력을 테스트하도록 설계되었다. 일반적인 사용 사례를 다루고, 모델을 차별화할 수 있는 도전적인 질문에 중점을 두었다. MT-bench를 구성하기 위해 8가지 일반적인 사용자 프롬프트 카테고리를 정하고, 각 카테고리에 대해 10개의 다중 턴 질문을 수작업으로 설계되었다.
카테고리: 글쓰기, 역할극, 추출, 추론, 수학, 코딩, 지식 I(STEM), 지식 II(인문/사회 과학)

Chatbot Arena는 크라우드 소싱된 배틀 플랫폼으로 사용자가 동시에 두 개의 익명 모델과 상호작용하여 동일한 질문 중에 선호하는 응답을 제공한 모델에게 투표하는 방식으로 데이터가 수집된다. 약 30K(3만) 건의 투표를 수집하였고, 미리 질문을 정의하지 않고 사용자들의 다양한 관심사에 따라 제한 없는 사용 사례와 자연 상태의 투표 데이터를 수집하였다는 특징이 있다.
LLM as a Judge
이 논문에서는 MT-bench와 Chatbot Arena를 사용하여 정답이 없는 개방형 질문에 대해 LLM으로 평가하는 방법인 "LLM-as-a-Judge"를 제안한다. 핵심을 요약하면 GPT-4를 평가자로 사용하며 3000개의 통제된 전문가 투표와 3000개의 크라우드소싱된 인간 투표 결과에서 80% 이상의 일치율로 인간 평가와 일치함을 확인했다.
이 결과는 기존의 능력 기반 벤치마크와 새로운 선호도 기반 벤치마크를 LLM-as-a-judge와 결합함으로써 모델의 핵심 능력과 인간 선호도를 고려한 평가 가능해졌다는 것을 의미한다.

LLM-as-a-Judge의 유형
이 논문에서는 세 가지 LLM-as-a-judge 방식을 제안하고 이는 독립적으로 또는 조합하여 구현 가능하다.
Pairwise comparison
LLM 평가자에게 하나의 질문과 두 개의 답변이 주어지며, 더 나은 답변을 선택하거나 무승부를 선언하는 임무를 부여
참가자 수가 증가하면 가능 쌍(pair)의 수가 기하급수적으로 증가하기 때문에 확장성이 부족하다는 단점이 있다.
Single answer grading
LLM 평가자에게 하나의 답변에 직접 점수를 부여하도록 요청하는 방식으로 이는 특정 쌍 간의 미묘한 차이를 구분하지 어려울 수도 있다는 특징이 있다. 또한 LLM이 절대 점수를 매기는 것은 상대적인 Pairwise 결과보다 변동성이 클 가능성이 높아지므로 결과가 불안정해 질 수 있다.
Reference-guided grading
참조 답변을 제공하여 점수를 매기는 방식이다. 참조 답변은 예상되는 답변이 될 수도 있고, 또는 수학 문제의 경우 해당 문제의 정답을 참조 답변으로 주기도 한다.
LLM-as-a-Judge의 장점 및 한계
LLM-as-a-Judge의 장점은 명확하게 확장성과 설명 가능성이 있다.
확장 가능한 벤치 마크와 빠른 반복이 가능하다는 것과 LLM 평가자는 점수뿐만 아니라 설명도 제공한다는 장점이 있다.
그러나 분명한 한계도 존재한다.
한계 1) 위치 편향 (position bias)
위치 편향은 LLM이 특정 위치를 다른 위치보다 선호하는 경향을 나타낼 때 발생한다.
이는 인간의 의사 결정이나 다른 머신러닝에서도 나타나기도 하며 이 편향의 원인으로는, 훈련 데이터에서 비롯되었거나, 인과적 변환기(causal transformer)의 좌에서 우로 읽는 구조에서 기인했을 가능성을 의심했다. 그러나 이는 향후 과제로 남겨두었다.

위와 같이 두개 A, B 모델의 응답을 판단하게 한 뒤에, 위아래 위치만 바꿔서 응답을 요청하니 일관성이 없는 답변을 하는 위치 편향을 보인다는 것이다.
위치 편향 관련 실험
이와 관련된 실험으로는 편향이 위치에 있는지, 아니면 이름에 있는지를 확인하는 실험을 진행했다.

세 가지 LLM을 두 가지 다른 프롬프트로 테스트를 진행했다고 한다.
default: 기본 프롬프트
rename: 기본 프롬프트 + 어시스턴트의 이름을 변경
그 결과는 모든 모델이 강한 위치 편향을 가지고 있었고, 대부분의 LLM 평가자는 첫 번째 위치를 더 선호했다.
또한 Claude-v1은 "rename" 프롬프트에서 "Assistant A"를 더 선호하는 이름 편향도 나타났고, GPT-4만이 60% 이상의 일관된 결과를 출력했다고 한다.
한계 2) 장황성 편향(verbosity bias)
더 길고 장황한 응답을 선호하는 현상을 의미한다. 짧지만 명확하고 질 높은 답변보다도 장황한 답변을 더 높이 평가하는 경향을 보일 때 발생하는 것이다.
장황성 편향 관련 실험
"반복 리스트(repetitive list)" 공격을 설계하여, 23개의 모델 답변에서 번호가 매겨진 리스트를 선택한 후 GPT-4를 통해 해당 리스트를 불필요하게 장황하게 만들도록 요청하였다. 그리고 새로운 정보는 추가되지 않으며, 원래 리스트를 다시 표현하여 그 앞부분에 추가하는 방식으로 반복 리스트를 만든다.
결과적으로 GPT-4를 제외한 다른 LLM 평가자들은 동일한 답변에 대해 항상 동점을 반환했지만 더 고급스러운 "반복 리스트" 공격에는 통과하지 못했다.

한계 3) 자기 강화 편향(self-enhancement bias)
LLM 평가자가 자신이 생성한 응답을 더 선호하는 경향이 있다는 것을 말한다. 이는 일부 LLM 평가자가 특정 모델을 선호하는 경향이 있는 것을 확인되었다. GPT-4는 자신의 응답을 10% 더 높게 평가했으며, Claude-v1은 25% 더 높게 평가했다. 그러나 흥미로운 점은 GPT-3.5는 자신을 더 높게 평가하지 않았다고 한다.
그 외에도 수학 및 추론 문제를 채점하는 데 한계가 있어, 정답을 정확히 알지 못하기 때문에 이러한 문제들을 채점하는 데 실패하는 경우가 많았다고 한다.
한계에 대한 해결 방안 제시
이 논문에서는 위치 편향과 수학 문제 채점 능력의 한계를 해결하기 위한 방법 제시했다.
먼저 위치 편향은 두 답변의 순서를 바꾸어 평가를 두 번 진행하여 순서에서 모두 동일한 답변이 선택되는 경우만 승자 선언하는 것이다. 그리고 Few-shot judge 방법도 제안했다. Few-shot 예시를 통해 위치 편향의 일관성을 높였다고 한다. (그러나 일관성은 올라갔지만 그게 정확도 향상을 의미하는 것은 아니라고 한다 (뒤에 추가 자료 존재))
수학 문제 채점을 위해서는 Chain-of-thought와 참고 Reference-guided judge을 활용하는 것을 제안했다. CoT기법을 통해 문제를 독립적으로 먼저 풀고 평가를 시작하라고 요청하는 프롬프트하거나, Reference-guided judge으로 참고 정답으로 사용하여 채점하도록 요청하는 방법이 있다.
또는 프롬프트로 해결이 되지 않을 때는 Judge LLM 모델을 파인튜닝하는 것도 하나의 방법으로 제시했다.
Agreement Evaluation
그렇다면 정말 이 LLM-as-a-judge의 평가 결과가 얼마나 신뢰성이 있는지를 어떻게 알 수 있는지가 궁금할 것이다. 그래서 이 저자는 LLM-as-judge와 인간 평가자들 간의 Agreement를 MT-bench와 Chatbot Arena 데이터셋에서 평가했다.
평가 데이터 셋
MT-bench은 Judge LLM 모델들과 58명의 전문가 수준의 인간 라벨러가 참여했고, Judge LLM 모델들이 모든 답변 쌍을 평가하도록 하고, 각 인간 판정자는 최소 20개의 무작위 다중 대화 질문을 평가하도록 요청했다. 약 3,000개의 투표로 agreement를 평가했다.
Chatbot Arena에서는 3만 개의 Arena 데이터에서 3천 개의 단일 대화 투표를 무작위로 추출했다.
Metrics는 두 종류의 판정자 간 Agreement이다. Agreement는 각 판정자 유형에서 무작위로 선택된 두 명(동일하지 않은)이 무작위로 선택된 질문에 대해 일치하는 확률로 정의한다.
평가 결과
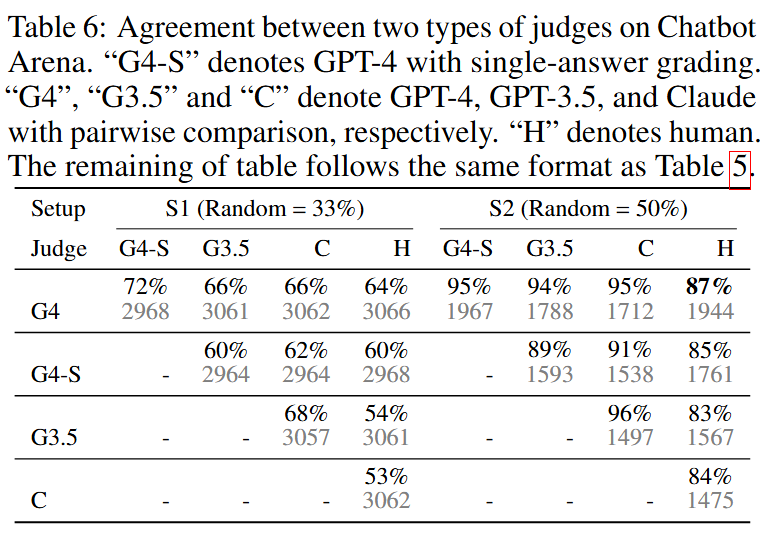
MT-bench에서 GPT-4는 Pairwise comparison와 Single answer grading 평가 모두에서 인간 전문가와 매우 높은 일치를 보였다. 특히 S2(동점 제외)에서는 GPT-4와 인간 간의 Agreement는 85%에 이르며, 이는 인간들 간의 Agreement인 81%보다도 높은 확률이다.
추가로 흥미로운 점은 인간의 선택이 GPT-4의 판단과 다를 때, GPT-4의 판단을 인간들에게 제시하고 그것이 타당한지 물었다고 한다. 이때 인간 평가자들은 서로 다른 관점에도 불구하고 75%의 경우 GPT-4의 판단을 타당하다고 보았고, 34%의 경우 자신의 선택을 바꾸는 데도 동의했다고 한다.

Chatbot Arena에서는 인간들과의 비동점 Agreement 비율은 유사하지만, GPT-4의 비동점 투표수가 훨씬 더 많았다.
이것이 의미하는 것은 GPT-4가 더 확신을 가지고 판단하며 위치 편향에 덜 영향을 받는다는 것을 의미한다. 다른 모델들도 확신을 가지고 답변을 줄 때, 성능이 좋다는 것을 확인했다.
두 표에서 단일 답변 평가를 사용한 GPT-4는 쌍별 비교를 한 GPT-4와 인간 선호도 모두와 매우 잘 일치한다. 이것의 결과 역시 GPT-4가 상대적으로 안정적인 내부 평가 기준을 가지고 있다는 것을 의미한다.
모델 성능과 인간의 일치도

동점이 아닌 투표만 포함했을 때, 모델 쌍 간의 성능 차이(즉, 더 큰 승률 차이)에 따라 GPT-4와 인간 간의 Agreement가 점진적으로 증가하여 70%에서 거의 100%에 이르는 것을 보여주는 그림이다. (그런데 이 말은 모델 간의 성능 차이가 크면 그만큼 평가하기 쉽기 때문에 인간과 더 잘 일치함을 의미하는 당연한 결과이지 않나 싶다..)
Win rates under different judges
MT-bench와 Chatbot Arena에서 다양한 판정자들에 따른 모델들의 평균 Win Rate를 각각 Figure 3와 Figure 4로 보여주었다.
LLM 판정자들의 Win rate 곡선은 인간 판정자들의 곡선과 매우 유사함을 알 수 있다.


Discussion
이 논문의 한계로는 챗봇 어시스턴트에게는 Honesty와 harmlessnes도 중요한 요소인데 helpfulness에 중점을 두고, safety에 대해서는 크게 다루지 않았다는 점을 인정했다. 또한 helpfulness에도 정확성, 관련성, 창의성 등 여러 차원이 존재하지만, 본 연구에서는 이들을 하나의 단일 메트릭으로 통합하여 평가했다.
여기까지 "Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena" 논문의 전체 내용은 모두 리뷰했다. 이후는 논문의 부록으로 있는 추가 실험이기 때문에 관심이 있는 사람은 참고해서 보면 좋을 것 같다.
그리고 논문에 참고할 만한 프롬프트 예시가 있고, hugging face에서도 예제가 있기 때문에 직접 실험해 보면서 프로젝트에 활용가능한지 테스트해봐도 좋을 것 같다.
Additional Experiments
이 실험은 Judge llm 모델의 일관성을 평가하기 위한 실험이다. rename, score, short로 프롬프트를 변경해서 실험하였다.
rename: 모델 이름을 변경
score: 모델이 어느 것이 더 좋은지 대신 두 개의 절대 점수를 출력하도록 기본 프롬프트를 변경
short: “위치 편향을 피하십시오..”, “평가를 시작하십시오... 그리고 간단한 설명을 제공하십시오”와 같은 지시 사항을 제거하여 기본 프롬프트를 단순화한 버전
그 결과는 score 프롬프트는 아래와 같이 나왔고, GPT-3.5의 일관성을 높일 수 있지만 Claude-v1과 GPT-4에서는 감소한 것을 볼 수 있다.

- Biased toward first: 첫 번째 모델로 위치 편향이 있는 경우
- Biased toward second: 두 번째 모델로 위치 편향이 있는 경우
- Consistency: 일관성
또한 카테고리별로 위치 편향 실험을 진행했을 때, 글쓰기 및 STEM(과학, 기술, 공학, 수학) 및 인문학 지식 질문과 같은 개방형 질문에서 더 두드러졌다고 한다. 그리고 수학 및 코딩의 경우, Judge LLM은 자신감이 더 높지만 그들의 종종 잘못된 판단을 내리기도 했다.
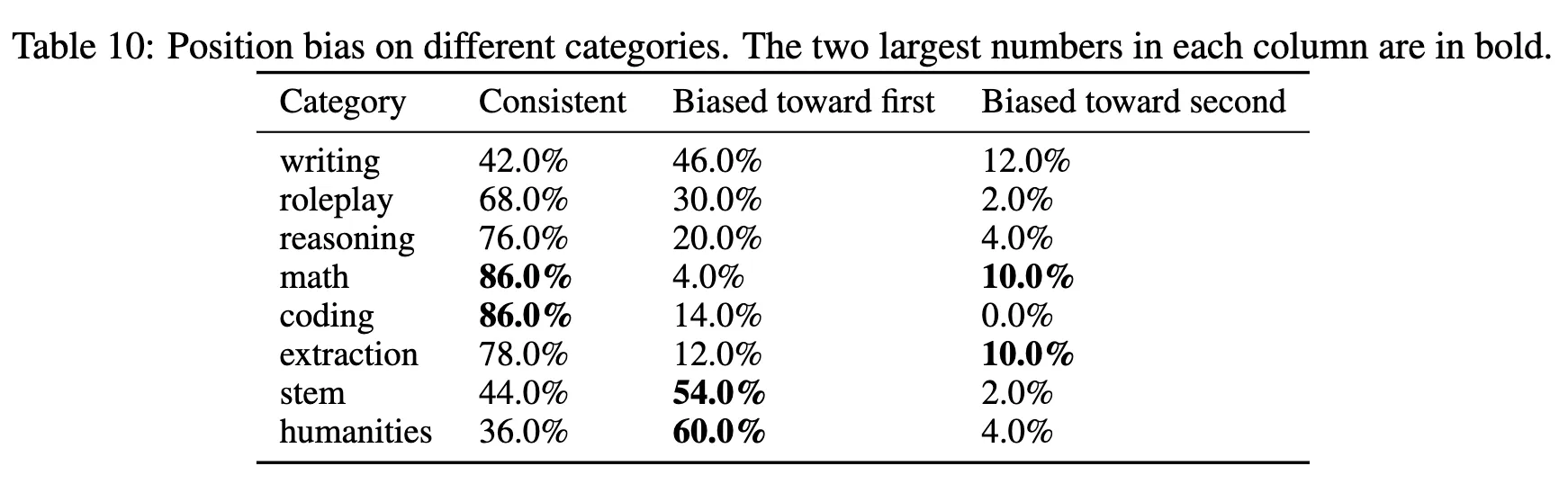
다음은 GPT-4와 기본 프롬프트를 사용하여 세 가지 서로 다른 모델 쌍을 평가함으로써 모델 쌍이 위치 편향에 미치는 영향을 연구한 결과이다. 성능이 비슷한 모델 간에는 위치 편향이 더 두드러지며, 두 모델의 성능이 크게 차이가 날 때는 거의 나타나지 않은 경향을 보였다.

위치 편향을 해소하기 위한 방법으로 Few-shot prompt를 소개했었는데, 그것과 관련된 실험이다.
Few-shot prompt를 했을때 일관성이 모든 모델에서 향상되는 것을 볼 수 있었지만 이것의 의미가 정확한 판단을 했다는 것을 의미하지는 않는다.

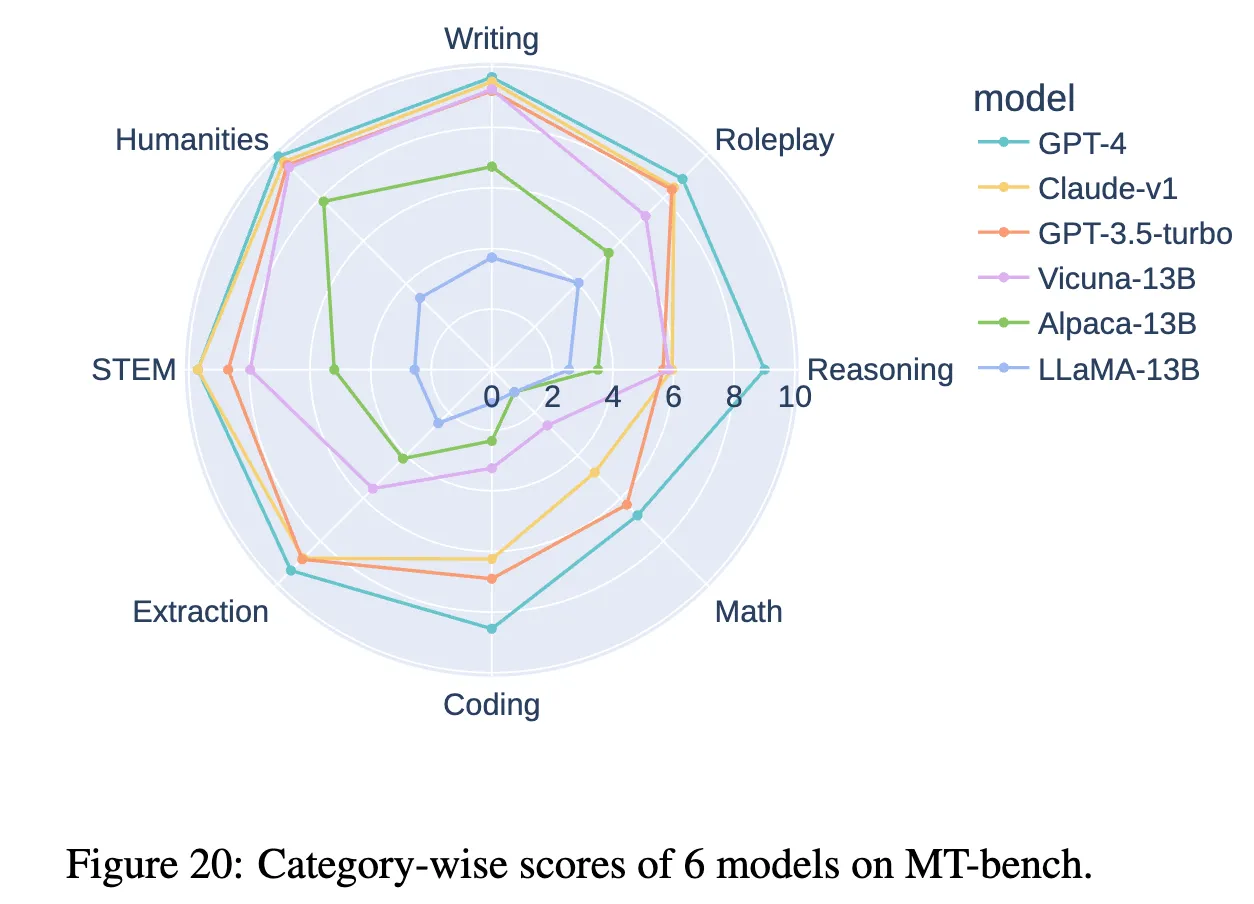
그리고 마지막으로 6개의 모델을 8개의 카테고리별로 single-answer grading를 이용해 나타낸 것이다. GPT-4가 모든 카테고리에서 가장 높은 점수를 얻은 것을 볼 수 있다.
'논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] Don't Do RAG: When Cache-Augmented Generation is All You Need for Knowledge Tasks (0) | 2025.01.19 |
|---|---|
| [논문 리뷰] Prompt Cache: Modular Attention Reuse For Low-Latency Inference (0) | 2025.01.05 |
| LoRA(Low-Rank Adaptation)를 파악해보자아앗!! (0) | 2024.08.09 |
| [논문 리뷰] A ConvNet for the 2020s (1) | 2024.03.24 |
| [논문 리뷰] CMT: Convolutional Neural Networks Meet Vision Transformers (0) | 2024.03.03 |



