
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 지도학습
- 결정트리
- Batch Normalization
- CASE WHEN
- NVL
- sorted
- ifnull
- recall
- layer normalization
- 웹서비스 기획
- 재현율
- 정밀도
- nvl2
- SQL
- 빠르게 실패하기
- 평가 지표
- 데이터 프로젝트
- five lines challenge
- 오차 행렬
- 감정은 습관이다
- 데이터 분석
- 비지도학습
- 강화학습
- 백엔드
- NULLIF
- 데이터 전처리
- Normalization
- DecisionTree
- beautifulsoup
- LAG
- Today
- Total
Day to_day
[지도 학습] 스태킹 모델에 대해서 자세히 알아보기! (구현 코드) 본문
❗본 포스팅은 권철민 선생님의 '파이썬 머신러닝 완벽가이드' 강의와 '파이썬 라이브러리를 활용한 머신러닝' 서적을 기반으로 개인적인 정리 목적 하에 재구성하여 작성된 글입니다.
포스팅 개요
앙상블 모델인 stacking 모델의 동작 과정에 대해 알아보고, 예제 코드와 stacking 모델의 장단점까지 알아보려고 한다.
아마 앙상블 모델의 마지막 포스팅이 될 듯하다.
스태킹 모델 Stacking model
앙상블처럼 개별 모델을 조합해서 메타 모델이 최종 예측을 하는 방법이다.
배깅, 부스팅과 가장 큰 차이점은 개별 알고리즘으로 예측한 데이터를 기반으로 다시 예측을 수행한다는 것이다.
핵심은 여러 개별 모델의 예측 데이터를 각각 스태킹 형태로 결합해 최종 메타 모델의 학습용 feature dataset과 테스트 feature dataset을 만드는 것이다.
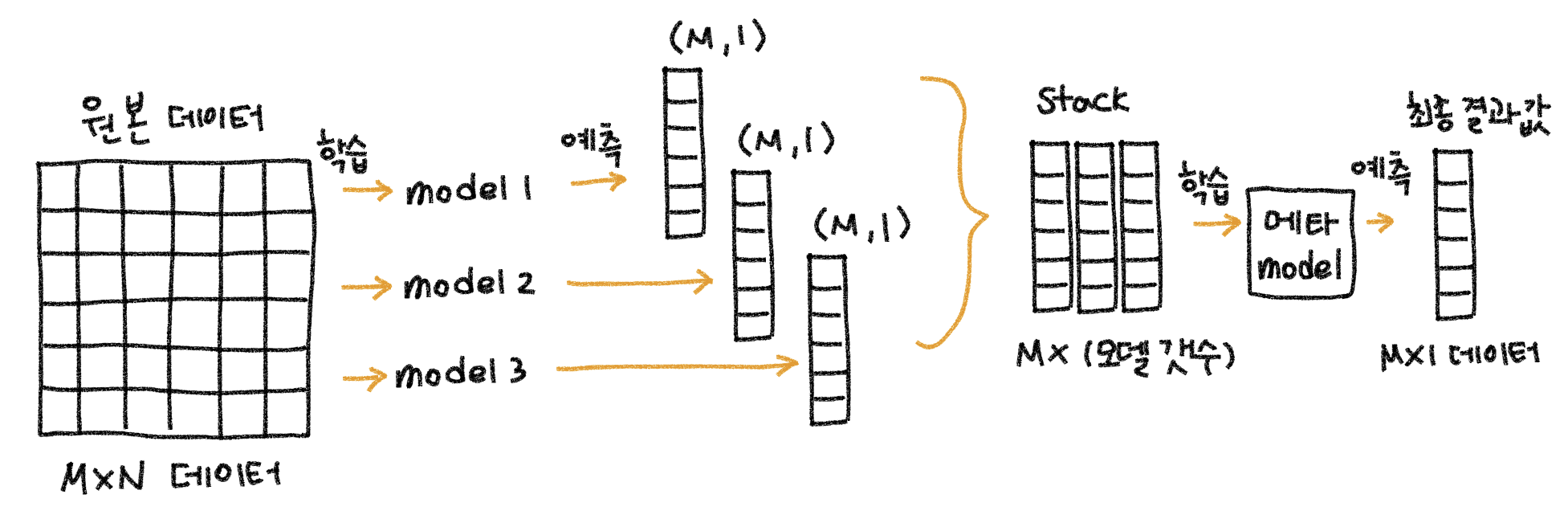
전체적인 과정을 보면 다음과 같다.
각 모델 별로 원본(학습 / 테스트) 데이터를 예측한 결과 값을 기반으로 메타 모델을 위한 학습용 / 테스트용 데이터를 생성한다.
1. 원본데이터(M x N)를 예시에서는 모델 3개로 학습 및 예측을 시킨다. 그러면 (M,1) 크기의 예측 결과가 나올 것이다.
2. (M, 1) 크기의 예측 결과를 스태킹 해서 (M x 3(모델 개수)) 크기의 새로운 메타 모델을 위한 학습용 데이터를 생성한다.
3. 메타 모델은 새로 만든 학습용 데이터로 학습하고, 예측하면 최종 결과가 나온다.
개별 모델에서 일어나는 과정을 좀 더 구체적으로 알아보자
그전에 아래의 그림은 권철민 선생님의 '파이썬 머신러닝 완벽가이드' 강의 자료임을 밝힌다.

보통 스태킹은 cross validation을 기반으로 스태킹을 한다.
학습 데이터셋 생성 과정
'model 1'이 학습과 예측을 하기 위해서 원본 데이터를 train data, test data로 나눌 것이다.
cv를 3으로 한다고 하면 폴드 1, 폴드 2는 학습용으로 사용하고, 폴드 3은 검증 폴드로 사용해서 예측 결괏값을 메타 모델 학습데이터의 세 번째 폴드에 넣는다. 이것을 반복하면, 폴드 2가 검증 폴드일 땐 두 번째 폴드에 넣고, 폴드 1이 검증 폴드일 때 첫 번째 폴드에 예측 결괏값을 넣어서 (M, 1)크기의 데이터를 만든다.
테스트 데이터셋 생성 과정
그러면 테스트 데이터의 경우 1) 폴드 1, 폴드 2만 가지고 학습한 모델이 예측한 결괏값, 2) 폴드 1, 폴드 3으로 학습한 모델이 예측한 결괏값, 3) 폴드 2, 폴드 3으로 학습한 모델이 예측한 결괏값을 모아서 최종 평균한 값이 메타 모델의 테스트 셋으로 쓰인다. 만약 원본 테스트 셋의 크기가 (K, N)의 shape을 갖고 있다면 결과 예측값은 (K, 1)로 나오고, 폴드가 3개라면 그것들을 평균해서 최종적으로 (K,1) 크기의 테스트 데이터가 만들어진다.
각각의 개별 모델에서 이 모든 과정을 거치면 거기서 나온 예측 결괏값을 합쳐서 최종적으로 메타 모델을 위한 학습데이터셋과 테스트 셋이 만들어진다.
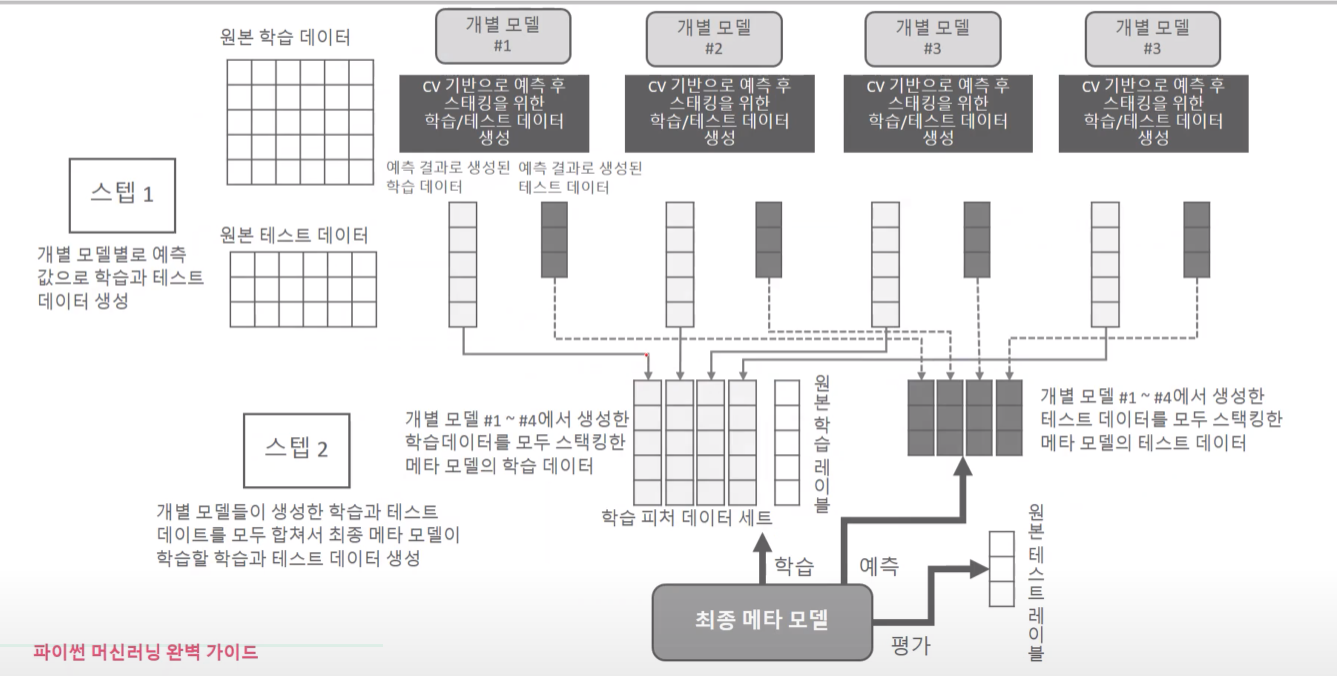
각각의 모델에서 학습 데이터로부터 예측한 (M,1)과 테스트 데이터로부터 예측한 (K,1)을 스태킹 한다.
만약 모델이 4종류였다면 최종 메타 모델의 학습 데이터 셋은 (M, 4)로 형성될 것이고, 테스트 데이터 셋은 (K, 4)로 만들어질 것이다.
평가는 원본 테스트 레이블로 평가한다.
[예제 코드]
개별 모델은 KNeighbors, RandomForest, AdaBoost, DecisionTree를 이용하고,
메타 모델은 Logistic Regression을 사용했다.
데이터는 사이킷런에서 제공하는 cancer 데이터를 이용했다.
개별 모델에서 일어나는 과정을 코드로 구현하면 다음과 같다.
# cross validation으로 stacking 함수로 만들기
from sklearn.model_selection import KFold
import numpy as np
def get_stacking_train_test(model, n_split: int, X_train, X_test, y_train):
kf = KFold(n_splits=n_split)
# train, test dataset 0으로 초기화 하기
# trainset shape: (M, 1), testset shape: (K, fold 개수)
train_data = np.zeros((X_train.shape[0], 1))
test_data = np.zeros((X_test.shape[0], n_split))
print('## {} train start'.format(model.__class__.__name__))
# KFold를 이용하여 학습 및 검증
for fold_num, (train_idx, val_idx) in enumerate(kf.split(X_train)):
# index에 따른 train, val set 재지정
X_tr, y_tr, X_val = X_train[train_idx], y_train[train_idx], X_train[val_idx]
# 학습
print("## {} fold train start".format(fold_num))
model.fit(X_tr, y_tr)
pred = model.predict(X_val)
# testdata에 대해서 학습
pred_test = model.predict(X_test)
# 초기화했던 것에 값 넣기
train_data[val_idx, :] = pred.reshape(-1,1) # 길게 한줄로 만들어서 넣기 reshape(-1,1)
test_data[:, fold_num] = pred_test
# testset 평균 내서 한 줄로 만들기
test_data = np.mean(test_data, axis=1).reshape(-1, 1)
return train_data, test_data
이제 개별모델을 함수에 대입하고, 리턴되는 train, test data를 합쳐서 최종 메타 모델의 train dataset과 test dataset을 만드는 과정을 코드로 구현한다.
# 모델별로 개별 train & test dataset 뽑아내기
kn_train, kn_test = get_stacking_train_test(kn_clf, 7, X_train, X_test, y_train)
rf_train, rf_test = get_stacking_train_test(rf_clf, 7, X_train, X_test, y_train)
ada_train, ada_test = get_stacking_train_test(ada_clf, 7, X_train, X_test, y_train)
dt_train, dt_test = get_stacking_train_test(dt_clf, 7, X_train, X_test, y_train)
# 메타 모델을 위한 train, test dataset 만들기
meta_train = np.concatenate((kn_train, rf_train, ada_train, dt_train), axis=1)
meta_test = np.concatenate((kn_test, rf_test, ada_test, dt_test), axis=1)
print(meta_train.shape) # (455, 4)
print(meta_test.shape) # (114, 4)
--------------------------------------------------------------------------------
# 시도했지만 실패한 코드
# 아래의 예시의 경우 dimension을 추가해서 합하게 된다.
# meta_train = np.array([kn_train, rf_train, ada_train, dt_train]) # shape: (4, 455, 1)
# meta_test = np.array([kn_test, rf_test, ada_test, dt_test]) # shape: (4, 114, 1)
마지막으로 메타 모델을 학습시켜 보고, 정확도를 구한다.
# 메타 모델 학습 시키기
# 메타 모델 : Logistic Regression
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
lr_clf = LogisticRegression(C=10)
lr_clf.fit(meta_train, y_train)
meta_pred = lr_clf.predict(meta_test)
print('메타 모델을 위한 trainset shape: {0}, testset shape: {1}'.format(meta_train.shape, meta_test.shape))
print('final accuracy: {:.3f}'.format(accuracy_score(meta_pred, y_test)))
[출력 결과]
메타 모델을 위한 trainset shape: (455, 4), testset shape: (114, 4)
final accuracy: 0.965
그런데.. 단일 모델로 학습을 시킨 것과 비교했을 때 정확도가 높긴 하지만 큰 차이는 못 느끼겠다ㅎ
# 개별 모델의 예측 성능 평가
from sklearn.metrics import accuracy_score
print('kn_clf accuaracy: {:.3f}'.format(accuracy_score(kn_pred, y_test)))
print('rf_clf accuaracy: {:.3f}'.format(accuracy_score(rf_pred, y_test)))
print('ada_clf accuaracy: {:.3f}'.format(accuracy_score(ada_pred, y_test)))
print('dt_clf accuaracy: {:.3f}'.format(accuracy_score(dt_pred, y_test)))kn_clf accuaracy: 0.939
rf_clf accuaracy: 0.965
ada_clf accuaracy: 0.974
dt_clf accuaracy: 0.939
스태킹 모델(Stacking model)의 장단점
[장점]
스태킹 모델은 여러 모델의 장점을 결합하여 모델의 정확도를 높일 수 있고, 단일 알고리즘으로 모델링하기 어려운 복잡한 데이터 셋을 처리하는 데 사용할 수 있다.
[단점]
스태킹은 계산 비용이 많이 들 수 있으며 좋은 결과를 얻기 위해서 상당한 조정이 필요할 수 있다.
또한 잘 조정된 단일 모델보다 성능이 항상 뛰어난 것은 아니다.
그리고 스태킹은 여러 모델을 조정하는 작업이 필요하기 때문에 최적의 조합을 찾기 위해 상당한 시행착오가 필요하다.
'Machine Learning > 지도 학습' 카테고리의 다른 글
| [지도 학습] 회귀 분석의 목적과 종류 (0) | 2023.05.07 |
|---|---|
| [지도 학습] 로지스틱 회귀 (Logistic Regression) (1) | 2023.04.22 |
| [지도 학습] LightGBM 개념과 예제 코드~! (1) | 2023.03.17 |
| [지도 학습] 여러가지 부스팅 알고리즘 알아보기 (GBM, Adaboost, XGBoost) (0) | 2023.03.15 |
| [지도 학습] 앙상블 배깅 유형 알아보기 (보팅 vs 배깅, 랜덤포레스트, 엑스트라트리) (0) | 2023.03.13 |



