
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 재현율
- 오차 행렬
- 정밀도
- 데이터 프로젝트
- NULLIF
- sorted
- Normalization
- 웹서비스 기획
- five lines challenge
- 비지도학습
- 평가 지표
- nvl2
- 데이터 분석
- Batch Normalization
- SQL
- 지도학습
- 강화학습
- layer normalization
- DecisionTree
- recall
- 백엔드
- 감정은 습관이다
- CASE WHEN
- ifnull
- LAG
- 결정트리
- 데이터 전처리
- beautifulsoup
- NVL
- 빠르게 실패하기
- Today
- Total
Day to_day
[지도 학습] 로지스틱 회귀 (Logistic Regression) 본문
❗본 포스팅은 권철민 선생님의 '파이썬 머신러닝 완벽가이드' 강의와 '파이썬 라이브러리를 활용한 머신러닝' 서적을 기반으로 개인적인 정리 목적 하에 재구성하여 작성된 글입니다.
포스팅 개요
분류 모델을 쭉 살펴보며 이름은 회귀가 들어가지만 분류 기법에 해당하는 '로지스틱 회귀'를 정리하려고 한다.
로지스틱 회귀란 무엇이고, 어떻게 사용할 수 있는지에 대해 가볍게 알아가고 넘어가겠다.
로지스틱 회귀 Logistic Regression
로지스틱 회귀는 선형 회귀 방식을 분류에 적용한 알고리즘이다.
Linear regression은 주어진 feature에 따라 예측 결괏값이 연속적이었다. 하지만 Logistic Regression은 타깃값이 연속적인 것이 아닌, 범주형이면서 0 또는 1인 경우 사용한다.
로지스틱 회귀는 이름은 회귀이지만 분류에 사용되고, 다른 선형 회귀처럼 회귀 최적선을 찾는 것이 아니라 시그모이드 함수의 최적선을 찾고, 이 시그모이드 함수의 반환 값에 따라 분류를 결정하는 것이다.

왼쪽의 선형 회귀 분석의 경우 독립 변수와 종속 변수 사이에 직선적인 형태의 관계가 있다고 가정한다. 하지만 오른쪽의 로지스틱 회귀는 주로 이진 분류(0과 1)에 사용된다.
로지스틱 회귀에 사용되는 함수는 시그모이드 함수 또는 로지스틱 함수라고 하는 0에서 1사이의 값만 반환하는 함수를 사용한다.
로지스틱 함수는 다음을 통해 정의되었다.
어떤 임의의 사건 A가 발생하지 않을 확률 대비 일어날 확률의 비율을 뜻하는 것을 Odds ratio(승산비)라고 한다.

확률 P(A)를 승산비로 변환하면 반환되는 값은 0부터 양의 무한대까지 값을 가질 수 있다. 바로 승산비를 로그 변환한 것이 로짓 함수(Logit function)이다. 로짓 함수는 아래와 같다.

로짓 함수는 로그 변환에 의해 음의 무한대부터 양의 무한대까지 값을 가질 수 있게 되었다.
로지스틱 함수는 로짓함수의 역함수이다. 즉 음의 무한대부터 양의 무한대까지 갖는 입력변수를 0부터 1 사이의 값을 가지는 출력 변수로 변환한 것이다.
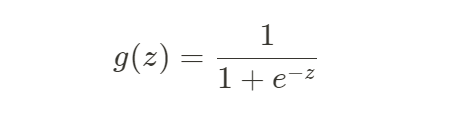

로지스틱 회귀에서 나오는 예측 값은 예측 확률을 의미한다. 예측 값. 즉, 예측 확률이 0.5 이상이면 1로, 0.5 이하이면 0으로 예측한다. 로지스틱 회귀의 예측 확률은 시그모이드 함수(로지스틱 함수)의 입력 값으로 들어가고 시그모이드 함수의 이진 분류를 통해 분류를 하게 된다.
0과 1을 예측하기 위해서 단순 회귀식을 적용할 순 없다. 그렇다면 시그모이드 함수에 확률을 대입해 0 또는 1로 분류할 수 있는데 이 과정에서 선형회귀를 적용한다.
Linear regression hypothesis로 사용했던 H(x) = w1x + w0를 대입하여 표현한다.
그러면 다음과 같은 식이 나오는데 결과적으로 시그모이드 함수의 w를 최적화하여 예측하는 것이 로지스틱 회귀의 목적이다.
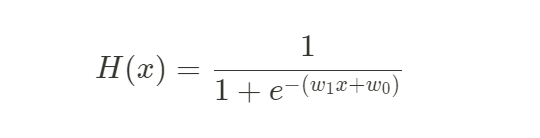
로지스틱 회귀 활용
로지스틱 회귀는 가볍고, 빠르고, 이진 분류 예측 성능이 뛰어나다는 장점이 있다.
특히 희소한 데이터셋 분류에서 성능이 좋아 텍스트 분류에 자주 사용된다.
로지스틱 회귀 파라미터
로지스틱 회귀의 주요 파라미터인 penalty, C, solver를 짚고 실습 코드로 넘어가겠다.
penalty : 규제 유형 L1 or L2
- L2 (default) : Ridge, 일반적으로 사용된다.
- L1 : Lasso, 변수가 많을 때, 모델의 단순화 및 해석에 용이하다.
C : 규제 강도를 조절하는 alpha 값의 역수
- C값이 작을수록 규제 강도가 큼 (단순 모델)
- C값이 클수록 규제 강도가 작음 (정규화 없어짐)
- C 값 기본값 = 1 (보통 10배씩 지정. 0.001, 0.01, 0.1, 1, 10..)
solver : 회귀 계수 최적화를 위한 다양한 최적화 방식
- lbfgs : solver의 기본 설정값, 메모리 공간 절약, CPU 코어 수가 많다면 최적화를 병렬로 수행 가능
- liblinear : 다차원이고 작은 데이터 세트에서 효과적으로 동작. but 국소 최적화 이슈가 있고, 병렬로 최적화할 수 있음
- sag / saga : 데이터 셋이 큰 경우 빠름
- 참고 : 작은 데이터 세트의 경우 'liblinear'가 좋은 선택, 큰 데이터 세트의 경우 'sag' 및 'saga'가 더 빠름
실습 코드
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV, train_test_split
# 데이터 셋: 유방암 데이터
cancer = load_breast_cancer()
X = cancer.data
y = cancer.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 학습 및 예측 함수 생성
from sklearn.metrics import accuracy_score, confusion_matrix, recall_score, precision_score, roc_auc_score, f1_score
def get_train_eval(model, X_train, X_test, y_train, y_test):
model.fit(X_train, y_train)
pred = model.predict(X_test)
pred_proba = model.predict_proba(X_test)[:,1]
accuracy = accuracy_score(y_test, pred)
recall = recall_score(y_test, pred)
precision = precision_score(y_test, pred)
f1 = f1_score(y_test, pred)
confusion = confusion_matrix(y_test, pred)
roc_auc = roc_auc_score(y_test, pred_proba)
print('오차 행렬')
print(confusion)
print('accuracy: {0:.3f}, recall: {1:3f}, precision: {2:.3f}, f1 score: {3:.3f}, AUC: {4:.3f}'.format(accuracy, recall, precision, f1, roc_auc))# GridSearchCV를 이용해서 최적의 파라미터 찾기
import warnings
warnings.filterwarnings('ignore')
lr_clf = LogisticRegression()
params = {
'penalty':['l1', 'l2'],
'C':[0.001, 0.01, 0.1, 1, 10, 100],
'solver': ['lbfgs', 'liblinear']
}
grid_search = GridSearchCV(lr_clf, param_grid=params, cv=5)
grid_search.fit(X_train, y_train)
print(grid_search.best_params_)
print(grid_search.best_score_)
[코드 실행 결과]
{'C': 100, 'penalty': 'l1', 'solver': 'liblinear'}
0.9670329670329672
# 학습 및 예측
lr_clf = LogisticRegression(penalty='l1', C=100, solver='liblinear')
get_train_eval(lr_clf, X_train, X_test, y_train, y_test)
[코드 실행 결과]
오차 행렬
[[42 1]
[ 1 70]]
accuracy: 0.982, recall: 0.985915, precision: 0.986, f1 score: 0.986, AUC: 0.996
'Machine Learning > 지도 학습' 카테고리의 다른 글
| [지도 학습] 규제 선형 회귀 L1, L2 norm (Ridge, Lasso, ElasticNet) (0) | 2023.06.16 |
|---|---|
| [지도 학습] 회귀 분석의 목적과 종류 (0) | 2023.05.07 |
| [지도 학습] 스태킹 모델에 대해서 자세히 알아보기! (구현 코드) (0) | 2023.03.20 |
| [지도 학습] LightGBM 개념과 예제 코드~! (1) | 2023.03.17 |
| [지도 학습] 여러가지 부스팅 알고리즘 알아보기 (GBM, Adaboost, XGBoost) (0) | 2023.03.15 |



