
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- five lines challenge
- 오차 행렬
- 재현율
- 평가 지표
- beautifulsoup
- Normalization
- SQL
- 감정은 습관이다
- 강화학습
- LAG
- recall
- Batch Normalization
- 백엔드
- NVL
- 데이터 프로젝트
- 데이터 전처리
- 비지도학습
- 웹서비스 기획
- sorted
- 정밀도
- NULLIF
- 데이터 분석
- CASE WHEN
- DecisionTree
- ifnull
- 빠르게 실패하기
- 결정트리
- layer normalization
- nvl2
- 지도학습
- Today
- Total
Day to_day
[논문 리뷰] CMT: Convolutional Neural Networks Meet Vision Transformers 본문
[논문 리뷰] CMT: Convolutional Neural Networks Meet Vision Transformers
m_inglet 2024. 3. 3. 16:07들어가며
Vision Trasformer 이후 더 발전된 Vision 분야에서 Transformer를 활용한 모델을 리뷰하고 있다.
이번엔 어떤 식으로 Vision Transformer의 한계를 해결했는지 궁금해진다. 오늘 리뷰할 논문은 CNN과 Transformer를 결합한 하이브리드 모델을 살펴보고자 한다.
CMT에서 알고 가야 할 점!
- CMT는 transformer base의 CNN을 결합한 hybrid network이다.
- Transformer의 장점인 멀리 떨어진 range 의존성에 대해서 포착하고, CNN의 local information 추출하는 것이 CMT의 강점이다.
CNN과 비교한 비전 트랜스포머의 문제
CNN대비 트랜스포머 기반 비전 모델의 성능이 떨어지는 이유
- 이미지는 트랜스포머 기반 모델에서 패치로 분할된다. → 시퀀스 기반 NLP와 이미지 기반 비전 작업의 근본적인 차이인 각 패치 내의 2D 구조와 공간적 로컬 정보를 무시한다는 것이 한계점이다.
- 트랜스포머는 고정된 패치 크기로 인해 저해상도, 다중 해상도 특징을 추출하기 어렵다.
- 트랜스포머의 self-attention 모듈의 계산 및 메모리 비용은 입력 해상도에 비례하여 quadratic(이차적)으로 늘어난다.
CMT 모델의 특징
- ViT와 비교하여, CMT의 첫 번째 stage에서 생성된 특징은 ViT의 H/16 ×W/16 대비 H/4 ×W/4로 더 높은 해상도를 유지할 수 있다.
- CMT는 CNN과 유사한 형태로 단계별 아키텍처를 채택하여 단계별로 해상도(시퀀스 길이)를 점진적으로 감소시키고 차원을 증가시킨다. → 다중 해상도의 특징 추출과 고해상도에 의한 계산 복잡도를 줄이기 위함이다.
- CMT Block을 살펴보면,
- LPU & IRFFN: 중간 특징 내에서 로컬 및 전역 구조 정보를 모두 포착하는 역할을 한다.
- ViT의 클래스 토큰 대신 Average Global Pooling을 사용한다는 특징이 있다.
Architecture

Hybrid architecture
- ViT와 같은 경우는(그림 b 참고), 이미지 patch를 입력으로 넣어 linear projection을 통해 합치기 때문에 기존 위치 정보가 많이 손실된다.
- CMT stem이라는 것을 활용해 그 한계점을 극복하고자, CMT stem은 ResNet의 앞 부분과 비슷한 방식으로(그림 a 참고) 입력을 처리하고 input 사이즈를 줄여 핵심 정보를 추출해 낸다.
- CNN 구조들과 동일하게 4 stage 기법을 사용하여 CNN의 표준 모형을 따라간다. → dense prediction task(픽셀단위로 예측하는 것)에 중요한 서로 다른 스케일의 feature map을 생성하기 위해 4개의 stage로 구성된다.
- 마지막은 GAP(Global Average Pooling)층과 FC를 거쳐 classification layer로 연결된다.
- 4 stage 중간마다 2*2 conv, 2 stride로 사용되어 CNN 구조와 같이 feature map의 scale을 점점 바꾸며 학습을 진행하는 효과가 있다. 이를 통해 입력 이미지에 대한 multi scale feature map 획득 가능하다.
- CMT는 LMHSA 및 IRFFN 이전에는 Layer Normalization을 유지하고, Convolutional layer 이후에 Batch Normalization을 삽입한다.
CMT Stem

입력 이미지 크기를 줄이기 위해 출력 채널이 32인 3x3 Conv를 사용하는 stem 아키텍처 활용한다.
3x3 Convolution(stride 2) 한 번하고, local 정보를 더 잘 추출하기 위해 stride 1인 또 다른 3x3 Conv을 두 번 사용한다.
CMT block
Transformer 블록을 개선하여 변형한 것으로 depth-wise convolution을 사용하여 local information을 강화하는 역할을 한다. CMT block은 크게 세 가지로 구성되어 있다.
1. LPU (Local Perception Unit)
- 지역 정보 추출하는 역할
2. LMHSA (Local-enhanced Multi-Head Self-Attention)
- long range dependency를 캡처, shortcut을 사용하여 gradient forward ability 향상
3. IRFFN (Inverted Residual Feed-Forward Network)
- Feed-Forward Network를 개선하여 더 나은 성능 제공
이를 통해 CMT 네트워크는 local feature과 longe range dependency를 모두 고려할 수 있다.
이제 하나하나 구성요소를 살펴보겠다.
CMT block : Local Perception Unit (LPU)


- local feature를 추출하기 위해 depth-wise conv를 사용한다.
- X는 stage의 입력 특징, DW Conv는 depth-wise convolution를 말한다.
Depth-wise Convolution이란?
일반적인 컨볼루션 연산과는 다르게 입력 채널마다 개별적으로 컨볼루션 필터를 적용하여 고유한 채널별 특징을 추출하고, 각 채널에서 얻은 결과를 합쳐서 최종 출력을 생성한다.
이는 입력 이미지의 공간적 특징은 보존하면서도 파라미터 수를 줄이고 메모리 사용량을 줄이는 효과가 있다. 모델을 더 경량화하고, 효율적으로 학습하고 실행할 수 있게 도와주는 기술이다.

CMT block : Lightweight MHSA



- 기존 Attention에서는 입력 X ∈ R n×d는 선형 변환을 통해서 query Q ∈ R n×dk, key K ∈ R n×dk 및 value V ∈ R n×dv로 변환(여기서 n = H × W는 패치의 수)한다.
- 반면 LightweightAttention은 계산 오버헤드를 줄이기 위해 Key와 Value를 생성하기 전에 k x k 필터를 stride=k로 두어 overlap 되지 않게 DW(DepthWise Conv)를 적용한다.
- DW(DepthWise Conv)을 적용하고 나서 K’은 ∈ R $\frac {n}{k^2}$ ×$d_k$, V’는 ∈ R $\frac {n}{k^2}$ ×$d_v$ 형태가 된다.
- 또한 Softmax 연산에 relative position bias B를 더해준다. Swin Transformer에서 제안되었던 방법은 단순히 상대적인 좌표를 계산 넣어준 반면에 B는 랜덤으로 초기화된 학습 가능한 파라미터로 사용된다.
- LMHSA는 h개의 헤드를 고려하여 정의되며 함수 입력에 적용된다. 각 헤드는 크기는 쭉 계산해 보면 nx(d/h) h의 시퀀스를 출력하고 이러한 h개의 시퀀스는 concat을 거쳐 n x d 시퀀스로 연결된다.
CMT block : Inverted Residual FFN
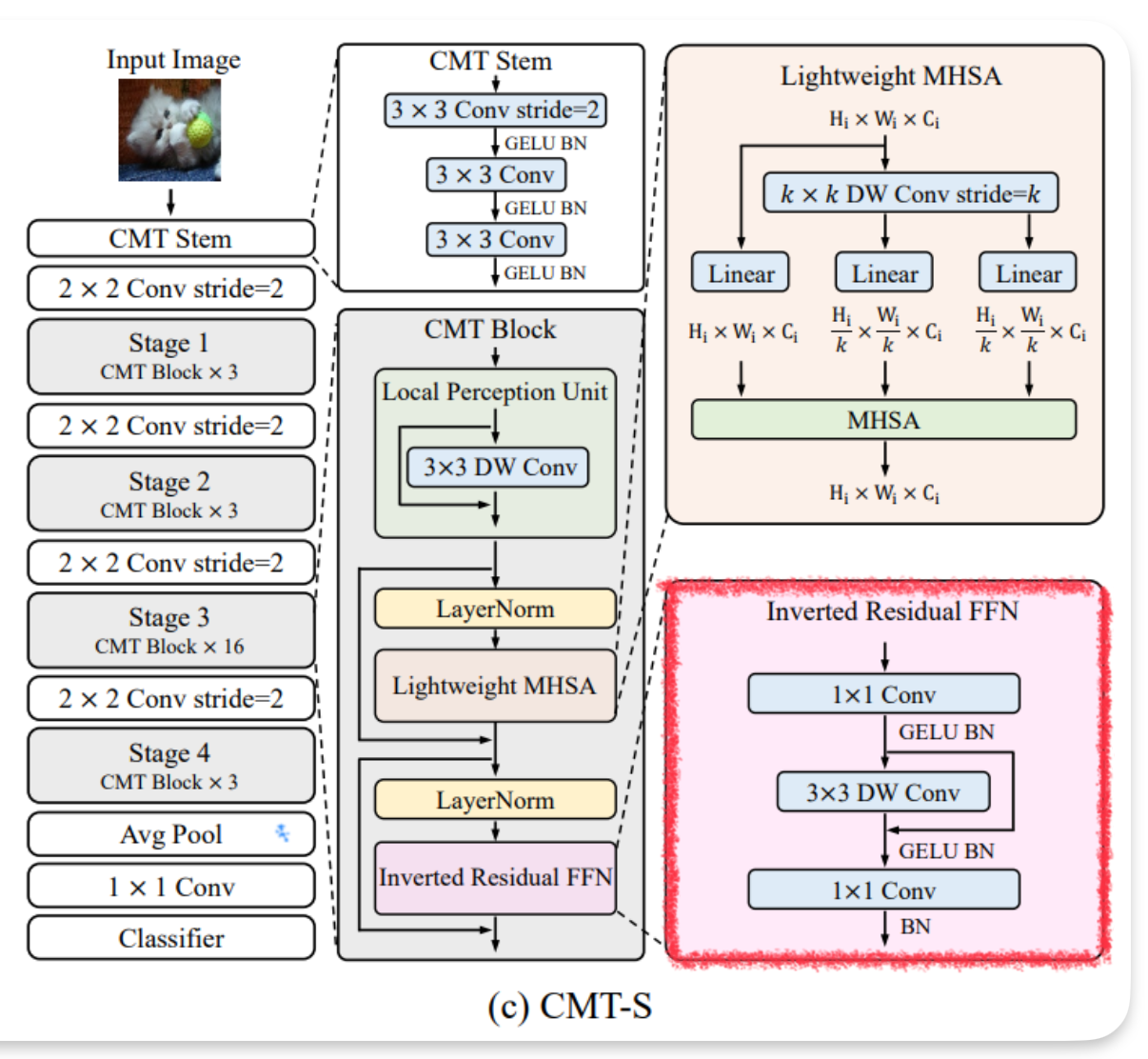

- Inverted Residual FFN은 1x1 conv 채널로 확장하여 3x3 DW Conv 연산을 수행하고 다음 1x1 conv에서 원래 채널로 되돌리고 activation function으로 Gelu를 사용했다.
- 여기서도 DWConv를 사용하여 더 적은 파라미터로 높은 성능을 냈다.
- Inverted Residual은 MobileNetv3에서 제안된 Relu로 인한 정보 손실을 방지하기 위해 제안되었음
Gelu (Gaussian Error Linear Unit)


Scaling Strategy

- Efficient Net에서 했던 방식과 같게 depth, dimension, resolution에 대해서 가장 최적값을 찾는 과정을 진행한다.
- $\phi$는 유저가 지정하는 값에 따라 FLOPS가 2.5의 $\phi$승만큼의 관계가 있다고 보면 된다.
결과


- ImageNet에 대한 결과이다.
- 음.. 근데 사실 잘 모르겠다. EfficientNet과 비교했을 때 resultion이 높은 이미지에 대한 실험은 없고, FLOPs도 크게 줄어든 것 같지 않은데 accuracy로만 비교하면 제일 좋아 보이지만 더 높은 해상도에 대한 실험은 없는지 궁금하기도 하다.
Reference
https://velog.io/@conel77/논문-리뷰CMT-Convolutional-Neural-Networks-Meet-Vision-Transformer



