
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- nvl2
- Batch Normalization
- five lines challenge
- 데이터 프로젝트
- 비지도학습
- NULLIF
- 데이터 전처리
- sorted
- layer normalization
- 결정트리
- 지도학습
- 빠르게 실패하기
- LAG
- SQL
- 재현율
- 감정은 습관이다
- ifnull
- CASE WHEN
- DecisionTree
- 웹서비스 기획
- NVL
- recall
- Normalization
- 정밀도
- 오차 행렬
- 강화학습
- 평가 지표
- beautifulsoup
- 데이터 분석
- 백엔드
- Today
- Total
Day to_day
ResNet 핵심만 빠르게! 본문
들어가며
다음은 인간의 한계를 넘어선 ResNet에 대해서 핵심만 빠르게 정리하면서 저자인 Kaiming He의 치밀한 논문까지 시간이 되면 읽어보면 좋을 것 같다.
이 내용은 혁펜하임님의 Legend 13 강의를 재구성한 것입니다.
ResNet의 핵심
- Residual Learning Block (잔차 학습 블록)
- 신경망을 깊게 만드는 방법으로 Residual block을 사용했다. 그래서 모델의 이름도 ResNet이 될 만큼 가장 중요한 블록이다. 입력값을 출력값에 직접 추가함으로써(skip connection) 학습 과정에서 레이어를 통과하는 정보의 손실을 방지하는 방법이다. 이를 통해 깊어질수록 학습이 잘 안되던 문제를 해결해 수백개의 레이어로 구성된 네트워크를 효과적으로 학습할 수 있게 하였다.
- Identity Shortcut Connection (항등 매핑 연결) ResNet에서는 레이어를 건너뛰는 연결을 사용하여, 입력과 출력의 크기가 동일한 경우에 한해 항등 매핑(Identity mapping)을 사용한다. 이 방법은 신경망을 효율적으로 학습시키는 데 도움이 된다.
- 깊은 네트워크 구조 ResNet은 깊은 네트워크를 구성하는 데 매우 효과적인데 VGG와 같은 다른 아키텍처들에 비해 ResNet은 수백 개의 레이어로 구성된 모델을 학습시킬 수 있다.
- Skip Connection ResNet에서는 입력값을 레이어를 건너뛰어 출력값에 직접 더하는 Skip Connection 또는 Shortcut Connection을 사용한다.
- Bottleneck 구조
ResNet에서 50 layer가 넘어가는 깊은 구조에서는 1x1 convolution을 이용하여 파라미터 수를 줄이기 위해서 차원을 축소했다가 복원하는 bottleneck 구조를 만들었다.
엄청나게 깊은 ResNet

VGGNet과 GoogleNet의 특징은 기존 우승했던 모델들에 비해 굉장히 깊어졌다는 특징이 있었다.
그래서 더 깊은 모델을 만들고자 하는 시도들이 많이 있었지만 모델이 깊어질 수록 underfitting이 된다는 것을 발견하게 된다. 그런데 ResNet은 무려 152개의 layer로 사람의 인식률을 뛰어넘을 만큼 높은 퍼포먼스를 보여주었다.
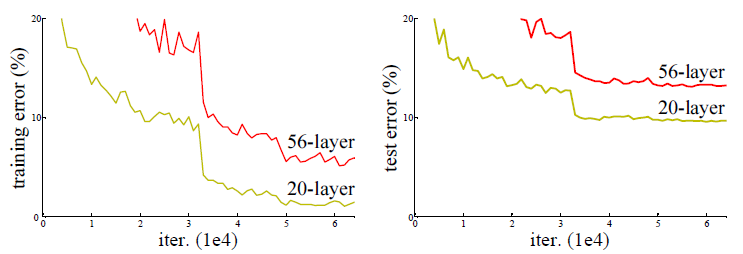
만약 깊이가 너무 깊어져서 overfitting이 난 것이라면 training에서는 error가 줄어드는 것이 정상이다. 그런데 train, test 모두 깊은 모델이 error가 더 높은 것으로 보아 optimization이 제대로 되지 않는다는 것을 알 수 있다. 이것은 ResNet의 저자인 “Kaiming He”도 알 수 없는 현상이라고 말했고, 나중에 loss function이 너무 복잡해진 탓에 이 현상이 발생한다는 연구가 발표되었다.
Shortcut Connection (Skip Connection)
ResNet의 가장 핵심이 되는 Shortcut Connection(Skip Connection)에 대해 살펴볼 것이다.
- 여기서 하나의 가정을 하는데 “적어도 얕은 모델만큼은 성능이 나와야 하는 게 아닌가?”하는 생각이다.
- 그래서 우선 더 얕은 모델의 가중치를 깊은 모델의 일부 레이어에 복사하고 나머지 레이어는 identity mapping을 하는 방법(input을 output으로 그냥 내보낸다는 의미)을 택한다.
- 이렇게 하면 적어도 shallow 한 모델만큼의 성능은 보장되지 않을까 하는 생각이다.

- 왼쪽 그림은 일반 CNN 과정을 나타낸 것이고 오른쪽은 Skip Connection의 구조이다.
- F(x) = relu(xW_1) W_2)
- H(x) = F(x) + x라고 가정하면 직접 H(x)를 학습시킨다기보다는 F(x) 즉 변화량만 학습할 수 있도록 만들어주자는 것이다. 이것이 skip connection을 도입한다는 의미이다.
그러면 왜 이 방법이 효과적인가?
여기서도 한 가지 필요한데 레이어가 엄청 깊은 모델이라면 입력으로부터 조금씩 값을 바꿔나가는 것이 이상적일 것이다. 그래서 그 말은 “변화량 F(x)는 그리 크지 않을 것이고, 결국 H(x)가 입력 x에 가까울 것이다.”라고 생각하는 것이다.

실제로 논문에 따르면, layer가 깊을수록 std가 더 작다는 실험 결과가 있다. 깊을수록 각 conv layer의 출력 편차가 작다는 것이다. 그것을 위의 그래프에서 plain-20, plain-56과 ResNet 모델들을 묶어서 비교해서 보면 알 수 있을 것이다.
그러면 H(x) = x로 만들려면 레이어의 출력 F(x)가 즉 변화량이 0에 가까워야 한다는 말이고, 그러면 weight matrix는 0에 가깝게 학습되어야 할 것이다.
반면 skip-connection이 없다면? H(x)를 x로 만들기 위해 weight matrix는 자기 자신이 나오게 하는 identity matrix가 되어야 할 것이다. 일반적으로 weight는 0 근처로 초기화되기 때문에 더 쉽게 학습이 될 것이다.
ResNet 아키텍처

- 첫 번째 그림인 VGGNet을 보면 사이즈를 줄이기 위해서 pooling layer를 넣어줬었다. 반면 ResNet은 맨 처음과 맨 끝을 제외하고는 pooling layer를 안 쓰는 대신 stride 2로 사이즈를 줄여주었다.
- 또한 skip connection을 하기 위해서는 dimension을 맞춰줘야 하기 때문에 점선은 1x1 convolution으로 사이즈와 채널수를 맞춰주는 역할을 한다.
- 그래서 논문에서 실선은 identity shortcut, 점선은 projection shortcut이라고 이름 지었다.
BottleNeck 구조
이전 포스팅에서 설명했던 GoogleNet(Inception) 모델을 다시 복기시켜보자.
GoogleNet에서 모델을 깊게 만들고 계산량을 줄이기 위해서 1x1 convolution을 사용했었다.
ResNet에서도 50 layer가 넘어가는 깊은 구조에서는 1x1 convolution을 이용하여 파라미터 수를 줄이는 bottleneck 구조를 만들었다.
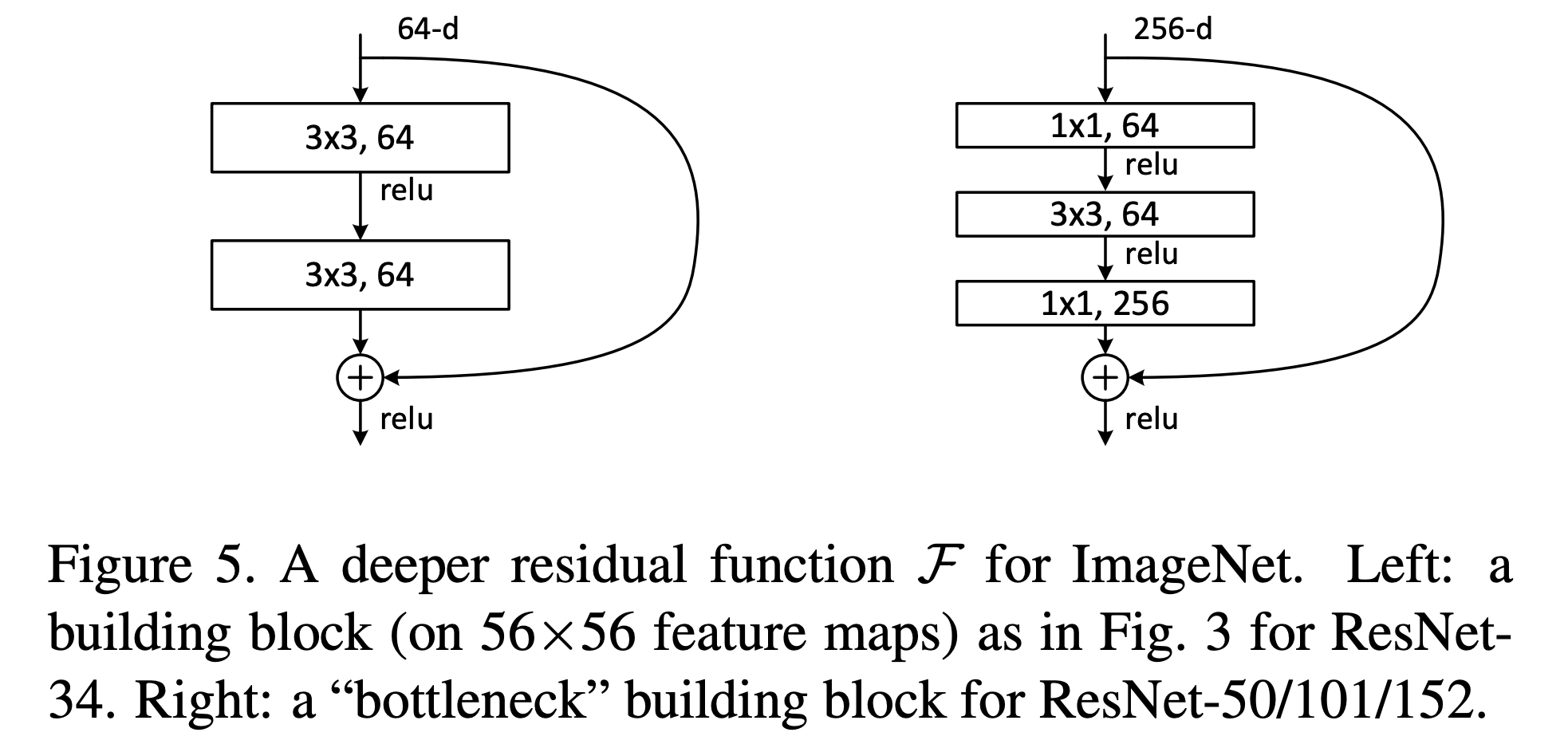
왼쪽의 그림은 ResNet-34 모델의 block을 보면 3x3 만 사용하고 있다. 그러나 깊은 레이어(50/101/152)에서는 BottleNeck block을 이용하는 것을 볼 수 있다.
ResNet의 BottleNeck Block은 다음과 같은 구조를 가진다.
- 1x1 convolution layer(차원 축소)
- 3x3 convolution layer
- 1x1 convolution layer(원래 차원 복원)
이 구조는 차원을 줄이는 1x1 convolution을 사용하여 연산량을 줄이고, 그다음 더 깊은 네트워크로 정보를 전달하기 위해 3x3 convolution을 사용한다. 이렇게 함으로써, 더 깊은 네트워크를 만들면서도 모델의 계산 비용을 낮췄다.
ResNet 모델의 전체 구조

논문에서 ResNet의 레이어에 따른 전체 구조를 볼 수 있다.
50개의 layer가 넘어가는 모델엔 bottleneck 구조가 있고, downsampling은 conv3_1, conv4_1 및 conv5_1에서 stride 2로 수행된다.
모델 결과

- SOTA 모델과 비교하여 top-5 error를 3.57% 까지 낮췄고, 6개의 ResNet 모델을 앙상블 해서 1등을 달성했다고 했다.
- 이 모델들은 각기 다른 깊이의 모델이고, ResNet-152는 2개 사용했다고 한다.
'Deep Learning' 카테고리의 다른 글
| GoogleNet (InceptionNet) 빠르게 핵심만! (0) | 2024.04.22 |
|---|---|
| VGGNet 아직도 정리 못했다면 빠르게 핵심만! (0) | 2024.04.01 |
| CBOW & Skip gram 개념 완벽 이해하기!! (0) | 2024.03.26 |
| Batch Normalization, Layer Normalization 비교 (5) | 2024.03.16 |
| 1 x 1 convolution이란? 직관적으로 이해해보기 (0) | 2024.02.25 |



