
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- layer normalization
- five lines challenge
- NULLIF
- 비지도학습
- sorted
- 데이터 전처리
- SQL
- 웹서비스 기획
- 결정트리
- 감정은 습관이다
- 오차 행렬
- DecisionTree
- nvl2
- 평가 지표
- beautifulsoup
- 재현율
- Batch Normalization
- 강화학습
- LAG
- 데이터 분석
- NVL
- recall
- 지도학습
- 백엔드
- Normalization
- CASE WHEN
- 데이터 프로젝트
- 빠르게 실패하기
- 정밀도
- ifnull
- Today
- Total
Day to_day
[지도 학습] LightGBM 개념과 예제 코드~! 본문
❗본 포스팅은 권철민 선생님의 '파이썬 머신러닝 완벽가이드' 강의와 '파이썬 라이브러리를 활용한 머신러닝' 서적을 기반으로 개인적인 정리 목적 하에 재구성하여 작성된 글입니다.
포스팅 개요
GBM 기반의 LightGBM에 대해서 간단하게 개념을 정리하고, 하이퍼 파라미터, 예제 코드 순서로 알아보기로 한다.
LightGBM
LightGBM은 GBM(Gradient Boosting Machine) 기반 알고리즘이다. GBM은 예측에 실패한 부분에 가중치를 더하면서 오차를 보완하는 식으로 순차적으로 트리를 만드는 것이다. LightGBM은 다른 트리기반 알고리즘과 다르게 수직적으로 확장한다. 그것을 리프 중심 트리 분할이라고 하는데 자세한 내용은 그림을 보면서 살펴보자.
LightGBM 분할 방식
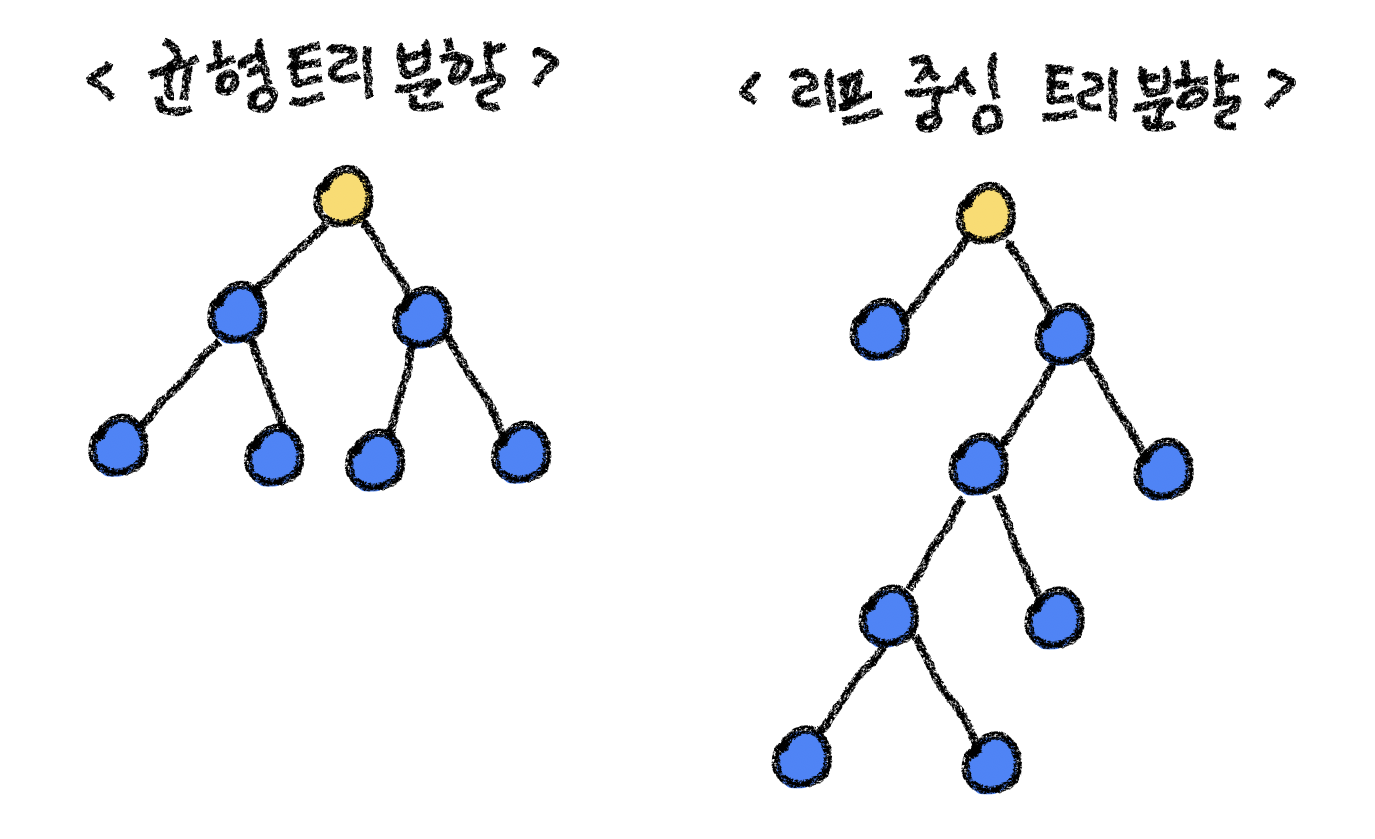
일반적인 트리 분할은 균형 트리 분할을 택한다. 대칭적으로 트리의 균형을 맞추며 깊이가 깊어지지 않게 하는 것이다.
반면에 리프 중심 트리 분할은 균형 트리 분할에 비해서 트리의 균형을 맞추지 않고 최대 손실 값(max data loss)을 가지는 leaf node를 지속적으로 분할하면서 깊이가 깊어지는 트리가 생성된다.
깊이가 깊어지는 것에 대해서 과적합 우려가 있지만 최대 손실 값을 가지는 리프 노드를 중심으로 지속적으로 분할하는 것이기 때문에 학습을 반복하면 결국 균형 트리 분할 방식보다 예측 오류 손실을 최소화할 수 있다.
또한 기존 GBM과 같은 경우는 트리의 균형을 맞추기 위해서도 시간을 썼기 때문에 더 빨라지는 장점이 있다.
LightGBM의 장단점
장점
- 더 빠른 학습과 예측 수행시간
- 더 작은 메모리 사용량
- 카테고리형 feature의 자동 변환과 최적 분할 (원-핫 인코딩등을 사용하지 않고도 카테고리 형 feature를 최적으로 변환하고 이에 따른 노드 분할 수행)
단점
- 데이터가 적은 경우 과적합 가능성이 크다.
LightGBM 하이퍼 파라미터 튜닝
- 트리구조
- max_depth
- num_leaves
- min_child_samples
- min_child_weight
- 샘플링 비율
- subsample : record 기반으로 100만건 있으면 거기에 몇 퍼센트를 할 것인가
- colsample_bytree : 컬럼 샘플링을 하지 않는 1이 기본값이나, 0.7~0.9 정도로 세팅하는 편이 일반적이다
- 손실 함수 규제 (loss값만 가지고 하면 overfitting 나기 쉬움)
- reg_lambda
- reg_alpha
주의 할 점
max_depth를 보통 트리 기반에서 기본 파라미터로 조정하는데 lightGBM의 경우 num_leaves를 더 많이 사용한다.
num_leaves의 개수를 중심으로 min_child_samples(min_data_in_leaf), max_depth를 함께 조정하면서 모델의 복잡도를 줄이는 것이 기본 튜닝 방안이다.
하지만 너무 많은 하이퍼 파라미터들을 튜닝하는 것은 오히려 최적값을 찾는데 방해가 될 수 있다. 적당한 수준의 하이퍼 파라미터의 개수 설정이 필요하다. (평균 6-7개 정도)
LightGBM Classifier 예제 코드
from lightgbm import LGBMClassifier
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# data load : 피마 당뇨병 데이터 셋
diabetes = pd.read_csv('../../data/diabetes.csv')
print(diabetes['Outcome'].value_counts())
# data split
y = diabetes['Outcome']
X = diabetes.drop('Outcome', axis=1, inplace=False)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=156)
# model training
lgbm_wrapper = LGBMClassifier(n_estimators=400)
evals = [(X_test, y_test)]
lgbm_wrapper.fit(X_train, y_train, early_stopping_rounds=100, eval_metric='logloss', eval_set=evals, verbose=True)
# predict
y_pred = lgbm_wrapper.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f'accuracy: {accuracy:.3f}')
# 결과
>> accuracy: 0.747
[LightGBM feature importance 코드]
from lightgbm import plot_importance
import matplotlib.pyplot as plt
%matplotlib inline
fig, ax = plt.subplots(figsize=(10, 12))
plot_importance(lgbm_wrapper, ax=ax)
plt.show()
'Machine Learning > 지도 학습' 카테고리의 다른 글
| [지도 학습] 로지스틱 회귀 (Logistic Regression) (1) | 2023.04.22 |
|---|---|
| [지도 학습] 스태킹 모델에 대해서 자세히 알아보기! (구현 코드) (0) | 2023.03.20 |
| [지도 학습] 여러가지 부스팅 알고리즘 알아보기 (GBM, Adaboost, XGBoost) (0) | 2023.03.15 |
| [지도 학습] 앙상블 배깅 유형 알아보기 (보팅 vs 배깅, 랜덤포레스트, 엑스트라트리) (0) | 2023.03.13 |
| [지도 학습 분류] 분류 예측의 불확실성 추정 개념 잡고 가기! (0) | 2023.02.12 |



