
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- Batch Normalization
- 감정은 습관이다
- 데이터 전처리
- 데이터 프로젝트
- SQL
- recall
- sorted
- beautifulsoup
- 백엔드
- 비지도학습
- 재현율
- DecisionTree
- nvl2
- 데이터 분석
- 평가 지표
- layer normalization
- Normalization
- five lines challenge
- NULLIF
- 웹서비스 기획
- 정밀도
- 빠르게 실패하기
- ifnull
- NVL
- 지도학습
- CASE WHEN
- 결정트리
- LAG
- 강화학습
- 오차 행렬
- Today
- Total
Day to_day
[지도 학습] 앙상블 배깅 유형 알아보기 (보팅 vs 배깅, 랜덤포레스트, 엑스트라트리) 본문
[지도 학습] 앙상블 배깅 유형 알아보기 (보팅 vs 배깅, 랜덤포레스트, 엑스트라트리)
m_inglet 2023. 3. 13. 22:58❗본 포스팅은 권철민 선생님의 '파이썬 머신러닝 완벽가이드' 강의와 '파이썬 라이브러리를 활용한 머신러닝' 서적을 기반으로 개인적인 정리 목적 하에 재구성하여 작성된 글입니다.
포스팅 개요
여러 개의 개별 모델을 조합하여 최적의 모델을 만드는 앙상블 기법에 대해서 공부해보려 한다.
앙상블 기법이 무엇인지, 그리고 그 유형은 어떤 것들이 있는지 살펴볼 예정이다. 이번 포스팅으로 끝날 것 같지 않아서 이어서 계속 업로드할 예정이다.
앙상블 학습이란? (Ensemble Learning)
앙상블 기법은 여러 개의 개별 모델을 조합하여 최적의 모델로 일반화하는 방법이다. 강력한 하나의 모델을 사용하는 것이 아닌 약한 모델을 여러 개 조합하면 더 정확한 예측을 하게 되고, 과대적합 문제를 앙상블에서는 감소시킨다는 장점이 있다.
앙상블의 특징은 단일 모델의 약점을 다수의 모델들을 결합하여 보완하고, 비슷한 모델을 합치는 것보다 약간 이질적인 모델들을 섞어서 성능 향상을 할 수 있다.
또 신기한 것은 뛰어난 성능을 가진 모델들로만 구성하는 것보다 성능이 좀 떨어지더라도 서로 다른 유형의 모델을 섞는 것이 오히려 전체 성능을 높일 수 있다.
앙상블 학습의 유형
앙상블 학습은 크게 보팅(Voting), 배깅(Bagging), 부스팅(Boosting), 스태킹(Stacking)으로 나눠 볼 수 있다.
이번 포스팅에선 보팅과 배깅에 대해 적어보기로 한다.
각각의 기법과 예시에 대해서 이제부터 설명하겠다.
보팅 vs 배깅
보팅과 배깅을 비교해서 보면 더욱 쉽게 기억할 수 있다.
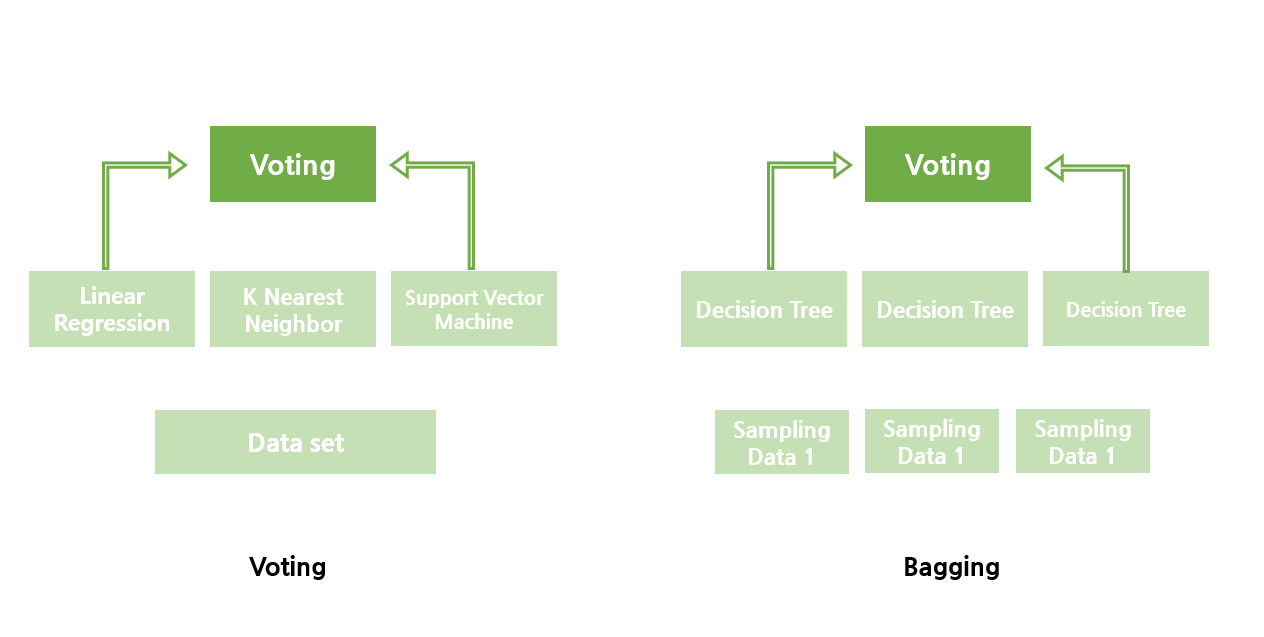
일단 보팅과 배깅은 여러 개의 분류기가 투표를 통해 최종 예측 결과를 결정하는 방식이다.
다른 점은 다음과 같다.
보팅 : 다른 종류의 분류기를 결합하는 것
배깅 : 각각의 분류기가 같은 유형의 알고리즘 기반이지만, 데이터 샘플링을 서로 다르게 가져가면서 학습 수행하는 것
보팅의 유형
보팅은 크게 두 가지 유형으로 나눠볼 수 있다.


하드 보팅은 한마디로 말하면 '다수결의 원칙'을 적용한다.
각각의 분류기는 예측을 하면 더 많은 예측결과가 최종 결과가 된다.
반면, 소프트 보팅은 클래스별 확률을 평균하여 결정한다.
predict_proba( ) 메소드를 이용하여서 클래스 별 확률을 결정하고
위의 예시를 보면 1로 예측하는 경우는 (0.7 + 0.2 + 0.9) / 3 = 0.6,
2로 예측하는 경우는 (0.3 + 0.8 + 0.1) / 3 = 0.4 이므로 1로 분류를 한다.
일반적으로 소프트 보팅이 성능이 좀 더 우수하다.
배깅 (Bagging)
배깅은 아까 보팅과 비교한 대로 같은 유형의 분류기이지만 데이터 샘플링을 다르게 하여 앙상블하는 기법이다.

배깅은 부트스트래핑 분할의 줄임말이다.
Bagging - Bootstrap Aggregating
부트스트래핑은 분할 방식인데 여러 개의 데이터 셋을 중첩되게 분리하는 것 '부트스트래핑 분할 방식'이라고 한다.
예를 들면 아래와 같다.

배깅의 대표적인 알고리즘 : 랜덤포레스트
앙상블 알고리즘 중 비교적 빠른 수행 속도를 보이며 다양한 영역에서 높은 예측 성능을 보인다.
여러 개의 결정 트리 분류기가 전체 데이터에서 배깅 방식으로 각자의 데이터를 샘플링해 개별적으로 학습을 수행한 뒤 최종적으로 모든 분류기가 보팅을 통해 예측을 결정한다.
개별적인 분류기의 기반 알고리즘은 결정 트리이지만 개별 트리가 학습하는 데이터 세트는 전체 데이터에서 일부가 중첩되게 샘플링된 데이터 세트이다. 이러한 여러 개의 데이터 세트를 중첩되게 분리하는 것을 부트스트래핑 분할 방식이라고 한다.
랜덤 포레스트는 각 트리는 비교적 예측을 잘할 수 있지만 데이터의 일부에 과대 적합 하는 경향을 가진다.
예를 들어 잘 작동하되 서로 다른 방향으로 과대적합된 트리를 많이 만들면 그 결과를 평균 냄으로써 과대적합된 양을 줄일 수 있다.
랜덤포레스트의 주요 하이퍼 파라미터
- n_estimators : 결정 트리의 개수, default 100개, 늘릴수록 학습 수행시간이 오래 걸린다.
- max_features : 랜덤포레스트의 기본 max_features는 'sqrt'이다. ( 만약 16개의 feature가 있다고 하면 루트를 씌운 4개의 feature만 랜덤 하게 가져와서 학습한다는 의미이다. (sub sample data의 수는 동일하다))
- max_depth, min_samples_leaf : 결정 트리에서 과적합을 개선하기 위해 사용되는 파라미터는 랜덤포레스트에 똑같이 적용된다.
랜덤포레스트의 장단점
장점
- 랜덤포레스트는 회귀와 분류에 있어서 성능이 뛰어나다.
- 데이터의 스케일을 맞출 필요가 없고, 매개변수 튜닝을 많이 하지 않아도 된다.
단점
- 많은 메모리를 사용하기 때문에 훈련과 예측이 느리다. (n_jobs = -1로 지정하면 컴퓨터의 모든 코어 사용)
사용 시 유의할 점
- 랜덤 하게 sample data를 뽑기 때문에 다른 random_state를 지정하면(혹은 아예 random_state를 지정하지 않으면) 전혀 다른 모델이 만들어진다.
- 텍스트 데이터같이 매우 차원이 높고 희소한 데이터에는 잘 작동하지 않는다.
- 중요한 매개변수는 n_estimators, max_features, max_depth가 있다.
- n_estimators는 클수록 좋고, 더 많은 트리를 평균하면 과대적합을 줄여 안정적인 모델을 만들 수 있다.
- 분류에서는 max_features = sqrt(n_features)가 default이고, 회귀에서는 max_features = n_features이다.
[예제 코드]
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import mglearn
# make_moons: 분류용 가상 데이터 생성
# noise: 가우시안 노이즈, X: shape(n_samples,2), y: shape(n_samples,)
X, y = make_moons(n_samples=100, noise=0.25, random_state=3)
# 가상 데이터 시각화
mglearn.discrete_scatter(X[:, 0], X[:, 1], y)
# data split
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=42)
# forest classifier 생성
forest = RandomForestClassifier(n_estimators=5, random_state=2)
forest.fit(X_train, y_train)
# 만들어진 트리는 estimators_에 저장됨
# 랜덤한 결정 트리의 예측 확률 시각화
fig, axes = plt.subplots(2, 3, figsize=(20,10))
for i, (ax, tree) in enumerate(zip(axes.ravel(), forest.estimators_)):
ax.set_title('tree {}'.format(i))
mglearn.plots.plot_tree_partition(X, y, tree, ax=ax)
mglearn.plots.plot_2d_separator(forest, X, fill=True, ax=axes[-1, -1], alpha=.4)
axes[-1, -1].set_title('Random Forest')
mglearn.discrete_scatter(X[:, 0], X[:, 1], y)
위의 코드는 총 5개의 결정 트리를 만들어서 보팅을 통해서 최종적인 Random Forest 모델의 결과를 나타냈다.
그 외의 비슷한 앙상블 - 엑스트라 트리(Extra-Trees)
랜덤포레스트와 비슷하지만 후보 feature를 무작위로 분할한 다음 최적의 분할을 찾는다.
랜덤포레스트는 DecisionTreeClassifier(splitter=’best’)로 설정되어 있는 반면 Extra-Trees에서는 splitter='random'로 설정되어 있다. 이렇게 하는 이유는 랜덤포레스트는 feature에 대한 정보이득을 계산하고, 가장 높은 정보 이득을 가지는 feature를 split node로 선택하여 가장 최선의 feature를 선정한다. 하지만 이 과정은 연산량이 많이 든다.
그래서 엑스트라트리는 split 할 때 무작위로 feature를 선정하고, feature에 대해서 최적의 node를 분할한다. 성능이 낮아지긴 하지만 속도가 빠르고 과대적합을 막을 수 있다.
[엑스트라트리 결과]
후보 feature를 랜덤 하게 분할한 다음 최선의 분할을 찾기 때문에 개별 트리의 결정 경계가 더 복잡해진다.

다음 포스팅은 부스팅에 대해서 알아보고
부스팅의 모델은 무엇이 있는지에 대해 살펴보겠다.
'Machine Learning > 지도 학습' 카테고리의 다른 글
| [지도 학습] 로지스틱 회귀 (Logistic Regression) (1) | 2023.04.22 |
|---|---|
| [지도 학습] 스태킹 모델에 대해서 자세히 알아보기! (구현 코드) (0) | 2023.03.20 |
| [지도 학습] LightGBM 개념과 예제 코드~! (1) | 2023.03.17 |
| [지도 학습] 여러가지 부스팅 알고리즘 알아보기 (GBM, Adaboost, XGBoost) (0) | 2023.03.15 |
| [지도 학습 분류] 분류 예측의 불확실성 추정 개념 잡고 가기! (0) | 2023.02.12 |



