
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- beautifulsoup
- Normalization
- Batch Normalization
- CASE WHEN
- 오차 행렬
- 비지도학습
- NULLIF
- NVL
- 백엔드
- five lines challenge
- 빠르게 실패하기
- 재현율
- sorted
- 데이터 분석
- 정밀도
- 결정트리
- recall
- ifnull
- 데이터 전처리
- layer normalization
- DecisionTree
- 감정은 습관이다
- 지도학습
- 강화학습
- 웹서비스 기획
- 데이터 프로젝트
- LAG
- nvl2
- 평가 지표
- SQL
- Today
- Total
Day to_day
[논문 리뷰] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows 본문
[논문 리뷰] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
m_inglet 2024. 1. 29. 23:36
포스팅 개요
Vision Transformer에 이어서 마이크로소프트에서 발표된 Swin Transformer에 대해서 리뷰를 하려고 한다.
이 모델은 이름에서 볼 수 있듯이 Transformer 기반 모델이고 ViT의 한계점을 보완하여 더 발전된 형태로 이미지 task에 general하게 좋은 성능을 내는 모델이라고 한다.
Swin Transformer에서 주목해야 할 점!
1. ViT에서 모든 patch에 self-attention의 computation cost를 지적하며, Swin Transformer에서는 window로 나누어 해당 window 안에서만 self-attention을 수행하고, 그 window를 한번 shift 하고 다시 self-attention을 하는 모델이다.
2. CNN 기반의 모델을 완전히 대체하기는 어렵지만 Locality의 한계를 개선하고 Vision분야에 적용된 더 발전된 구조의 Transformer 모델이라는 것에 의미가 있을 것 같다.
3. 계층적 아키텍처(Hierarchical) 모델을 구성함으로써 다양한 스케일에서 모델링할 수 있으며 object detection, segmentation의 backbone으로도 좋은 성능을 낸다.
이미지 분야에서 기존 Transformer 기반 모델의 한계점은?
이 전에 리뷰했던 ViT의 한계로는 patch들이 모두 고정된 scale을 갖고 있고, 이미지는 단어에 비해 픽셀 해상도가 높기 때문에 특히 sementic segmentation과 같은 픽셀 수준의 예측이 필요할 때 고해상도 이미지에서 self-attention의 계산복잡도가 이차적으로 증가하기 때문에 (quadratic computational complexity to image size) 처리에 한계가 있었다.


Swin Transformer 개요

Swin Transformer의 핵심은 작은 patch 4x4 사이즈에서 시작해서 점점 패치들을 계층적으로 merge 해 가는 방식이다.
window내에 패치들끼리만 self-attention을 수행하는데 여기서 window는 빨간색 네모 칸이라고 생각하면 된다. 그림 b의 ViT 모델과 비교할 때 각 patch는 나머지 전체 patch에 대해 self-attention을 수행한다. 이 경우에 왜 계산 복잡도가 이차적으로 증가하는지에 대해서는 뒤쪽에서 식과 함께 설명하겠다.
Swin Transformer로 돌아가보면, 이미지의 크기가 224x224 px이라고 할 때 첫 번째 레이어 4x4 size의 patch가 56x56개 있을 것이다. 각 window 사이즈(M)를 7x7(default)로 하면 한 window에 49개의 patch가 있다. 그래서 총 8x8개의 window가 생긴다. 위의 설명이 잘 와닿지 않는다면 하나씩 계산해 보며 이해해 보면 좋겠다.
Model Architecture
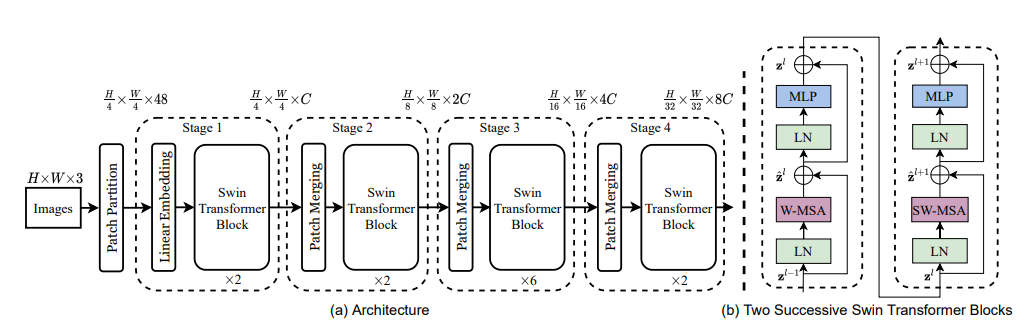
그림 a 먼저 살펴보면,
Patch Partition, Linear Embedding, Swin Transformer, Path Merging으로 구분이 되며 4개의 Stage로 이루어져 있다.
핵심 아이디어인 Swin Transformer Block은 오른쪽 그림 b와 같이 두 개의 encoder로 구성되어 있으며, 인코더 block내에 일반적인 MSA(Multi head Self-Attention)가 아니라 W-MSA, SW-MSA가 있는 것을 볼 수 있다.
또한 각 stage별로 Swin Transformer Block의 횟수(2/2/6/2)가 다르게 있는데 이것은 한 개의 block당 2개의 인코더가 붙어있는 구조이므로 세트로 묶어서 실제로는 1/1/3/1개의 block 세트가 반복된다고 이해할 수 있다.
그래서 우리는 계층적인 구조인 stage별로 간단하게 살펴보고, 각 block이 하는 역할에 대해서 자세히 알아보고자 한다.
계층적 구조
1. Patch Partition - 초기 세팅
- patch size (4x4)
- H/4 x W/4 x 48 (4x4x3)
2. Stage 1은 Linear embedding을 거쳐 C차원으로 사영된다. 이후 Swin Transformer block을 지나고 나서 H/4 x W/4 x C의 형태가 된다.
3. Stage 2부터는 "Patch Merging" 적용되는데 이 개념은 바로 뒤에서 설명하도록 하고 결과적으로는 해상도는 H/8 x W/8이고 출력 dimension은 2C로 설정된다.
4. 각 Stage를 지나며 patch 수가 4의 배수만큼 감소한다.
Patch Partition
ViT와 마찬가지로 이미지를 patch 단위로 쪼개고, patch는 일종의 토큰으로 취급된다.
patch size를 (4 x 4)라고 할 때 하나의 feature는 (4x4x3)=48의 shape을 갖게 된다.
Linear Embedding
Patch Partition 후에 linear Embedding을 진행하여 C의 차원으로 맞춰준다. 모델의 크기에 따라 Stage마다 정해진 차원수가 있으며 nn.Linear로 수행한다.
Patch Merging

Stage 2부터 사용이 되는 Patch Merging에서는 인접한 2x2=4개의 그룹의 feature를 연결하여 하나의 큰 patch를 새롭게 만든다. 이때 위의 그림과 같이 차원이 4C로 늘어나기 때문에 linear layer를 적용하여 2C로 조정한다.
Stage 2에서의 예를 살펴보면 patch merging을 하기 전 H/4 x W/4 x C에서 patch merging을 거치면 H/8 x W/8 x 2C의 형태로 변환이 된다. 결과적으로 patch 수(토큰 수)가 감소하며 해상도는 2배 다운 샘플링 되었고, 각 토큰의 차원은 두 배씩 늘어났다.
Swin Transformer Block

W-MSA (Window MSA)

Swin Transformer(왼쪽 그림)을 보면 현재 윈도우에 있는 패치끼리만 self-attention 연산 수행한다. 이것은 이미지는 주변 픽셀끼리 서로 연관성이 높기 때문에 윈도우 내에서만 self-attention 써서 효율적으로 연산을 줄이려는 것으로 CNN의 커널과 비슷하다.
ViT(오른쪽 그림)는 윈도우 기반의 계산 복잡도를 식으로 표현했을 때, MSA에서 이미지의 크기인 hw에 따라 연산량이 quadratic하게 증가한다. 그에 비해 Swin Transformer는 M(윈도우 크기)이 훨씬 작기 때문에 연산량이 크게 줄어든다. 또한 이미지의 해상도가 높을수록 hw가 더 커지는 ViT와 달리 M은 고정된 값이기 때문에 linear하게 된다.
SW-MSA (Shifted Window MSA)
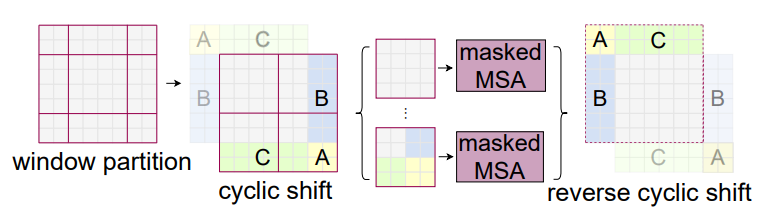
W-MSA를 수행함으로써 전체 patch에 대해 self-attention을 계산했던 ViT와 달리 Swin Transformer는 윈도우가 고정되어 있기 때문에 윈도우 내에서만 self-attention을 계산하여 윈도우 간의 연결성이 부족하다는 단점이 발생할 수 있다. 그래서 이 논문에서는 중복된 계산은 막으면서 효율적인 처리를 위해 Shifted Window MSA 기법을 제안한다. 그 방법은 아래의 과정을 따른다.
1. [M/2, M/2] 칸 떨어진 patch에서 window를 분할하여 우측 하단으로 shift 시킨다. (cyclic shift)
2. A, B, C는 서브 윈도우라고 칭할 때, feature map에서 인접하지 않는 서브 윈도우를 붙여서 window내에 중복되는 연산을 막고 효율적인 계산을 하도록 한다.
3. 마스크 연산 후엔 다시 원래 값으로 되돌린다. (reverse cyclic shift)
결과적으로 SW-MSA는 윈도우 사이의 연결성을 알아낼 수 있게 해 준다.
Relative Position Bias
마지막으로 기존의 ViT나 Transformer와 달리 Swin Transformer에서는 Position embedding을 처음에 더해주지 않는다.
대신 self-attention을 수행하는 과정에서 relative position bias를 더해준다.

절대 좌표가 아닌 상대 좌표를 더해주는 방법으로 M개의 patch가 하나의 window를 구성하므로 각 축을 따라 상대적인 위치는 [-M+1, M-1]의 범위 안에 존재할 것이다. 논문에서는 상대적인 좌표를 임베딩해서 더해주는 것이 효과적이라고 말한다. 상대 좌표의 장점은 양선형 보간을 통해 다른 윈도우 크기로 세밀 조정을 통해 모델을 초기화하는 데 사용될 수 있다고 한다. 양선형 보간(원본 영상을 N배 확대할 때 빈 cell을 보간법을 통해 채워넣는데 양선형 보간법을 통해 값을 넣는 것을 의미함)
Experiments
1) ImageNet-1K classification, 2) COCO object detection 3) ADE20K semantic segmentation를 실험하였다. 세가지 Task에 대해 성능 결과를 보여준다.
1) ImageNet classification

2) COCO object detection

3) ADE20K semantic segmentation

Reference
https://arxiv.org/pdf/2103.14030.pdf



