
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- Batch Normalization
- 백엔드
- 감정은 습관이다
- SQL
- ifnull
- 빠르게 실패하기
- 데이터 전처리
- 지도학습
- 결정트리
- LAG
- beautifulsoup
- CASE WHEN
- recall
- NULLIF
- 강화학습
- 평가 지표
- sorted
- 데이터 분석
- layer normalization
- nvl2
- 비지도학습
- 웹서비스 기획
- Normalization
- five lines challenge
- NVL
- 정밀도
- DecisionTree
- 오차 행렬
- 데이터 프로젝트
- 재현율
- Today
- Total
Day to_day
[논문 리뷰] A ConvNet for the 2020s 본문
들어가며
ViT모델을 시작으로 Vision Task에 적용된 여러 Transformer 기반의 모델이 많이 나왔다.
ConvNeXt 논문에서는 Standard ResNet의 디자인 방향을 점진적으로 modernize 시키면서 그 과정에서 모델 성능에 기여하는 여러 핵심 요소에 대해서 알아볼 예정이다. 다시 말하자면, Transformer의 Design Decision이 ConvNet의 성능에 어떤 영향을 미치는지에 대해 중점적으로 다루고 하나씩 바꿔가며 성능과 연산량 결과를 살펴볼 것이다.
특히 이 논문에서 저자가 강조하고 싶은 점은 많은 Transformer기반의 비전 모델이 나왔음에도 불구하고 "ConvNet 기반의 모델도 잘 디자인하면 좋은 성능을 충분히 낸다"는 것이다. 더불어 이 논문을 통해 컨볼루션의 중요성에 대해 다시 상기시키고자 하였다.
ConvNeXt의 구조 및 특징

ConvNeXt 모델은 convolution layer를 거친 후 fully connected layer로 이어지는 구조이다.
- 합성곱 레이어, 풀링 레이어, Fully Connected layer와 같은 다양한 레이어로 구성되었다.
- ResNet을 기반으로 디자인을 바꾼 것이기 때문에 구성은 ResNet과 비슷하지다. 여기서 특징이 되는 레이어는 GAP 레이어, Layer Normalization, GELU가 있다.
- GAP는 fully connected layer의 수를 줄이는 것을 목표로 하며, 이를 통해 더 가벼운 모델 구조를 얻을 수 있다. 그렇기 때문에 ConvNeXt 모델이 더 빠르고 더 적은 계산양을 갖고 있다.
- 또한 ConvNeXt 모델은 ‘layer normalization’ layer와 activation function으로 GELU를 사용하며 기존 ConvNet 기반의 모델에서는 잘 사용하지 않았던 것들을 추가하였다.
Modernizing a ConvNet: a Roadmap

ResNet 모델을 modernize하기 위한 로드맵을 보자.
일단 몇 가지를 바꿔가면서 CNN과 Transformer의 네트워크 성능을 비교한다. ResNet을 점차 modernize 하며 Swin Transformer구조로 향해 가볼 것이다. 이때 모델은 FLOPs(4.5x10⁹)가 서로 비슷한 ResNet-50과 Swin-T(tiny)를 비교하였다.
이 논문의 목표는 ViT 이전과 이후의 모델 간의 차이를 줄이고, 순수 ConvNet이 달성할 수 있는 한계를 테스트하는 것이다. 이를 위해 ResNet50을 기반으로 하여 hierarchical Transformer를 CNN으로 현대화하여, 성능을 점진적으로 향상한 ConvNeXt 모델을 제안한다.
Design Decisions는 크게 4가지로 나누어 볼 수 있다.
- Macro design
- ResNeXt
- Inverted bottleneck
- Large kernel size
- Micro design
Train Technique
기본적으로 Base model(ResNet-50/200)에 아래와 같은 train techniques를 적용하여 ResNet-50모델 성능을 76.1%에서 78.8%로 향상해서 진행하였으며 이 train technique은 모든 train에 동일하게 적용하여 학습하였다. 그리고 세 가지의 다른 random 시드의 평균으로 accuracy를 구하여 평가하였다. 또한 train과 evaluation은 동일하게 ImageNet dataset을 이용한다.
Train Techniques
- original 90 epochs에서 300 epochs까지 늘려서 진행
- AdamW optimizer 사용
- Data Augmentation 사용: Mixup, Cutmix, RandAugment, Random Erasing, regularization schemes including StochasticDepth, Label Smoothing
성능: 76.1% → 78.8%
Macro design
1. Stage 연산 비율 변경

- Swin-Transformer는 위의 구조와 같이 stage를 갖고 있고, 그 stage의 비율은 1:1:3:1을 가지고 있다. 그래서 ResNet-50에서 사용하는 residuel block도 (3,4,6,3)에서 (3,3,9,3)로 같은 비율로 변경했다.
- 성능: 78.8% -> 79.4%
- FLOPs: 4.1G → 4.5G
2. ‘Patchify’로 Stem 변경
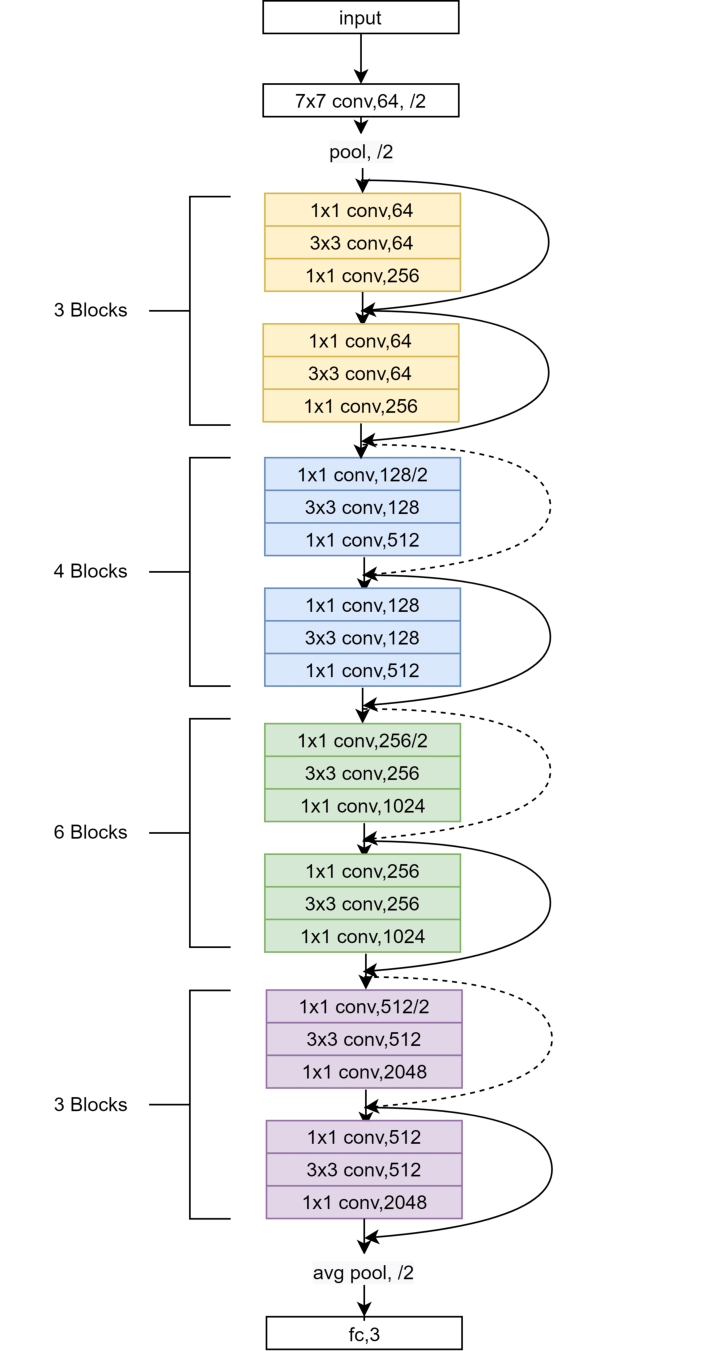
- 먼저, ResNet은 Stem 부분에서 7x7 필터와 stride 2, max pooling을 사용하여 입력 이미지를 4배 다운샘플링한다. 반면에 Vision Transformer는 이미지를 14x14 또는 16x16 패치로 나누며, Swin Transformer는 더 작은 4x4 패치로 이미지를 나눈다.
- 이에 따라 4x4 필터 크기에 stride 4를 적용하여, 합성곱을 수행하는 "patchify" 레이어를 만든다. 이는 Swin-T의 stem과 비슷한 작업을 수행하는 Non-overlapping convolution이라고 할 수 있다.
- 성능: 79.4% → 79.5%
- FLOPs: 0.1G 감소
ResNeXt

ResNeXt의 핵심 구성 요소는 grouped convolution이며 더 많은 그룹을 이용해 너비를 확장시키고 각자 연산 후 다시 concatenate하는 것이었다. 위의 예시에서는 input channel을 32개의 patch로 나누어 grouped convolution을 한다.


여기서 depth wise convolution을 이용하는데 이것은 채널당 정보를 혼합하는 self-attention의 가중 합 연산(Weighted Sum)과 유사하며, 공간 차원에서만 정보를 혼합한다. Depthwise conv와 1 × 1 conv을 결합하여 사용하는 것은 각 작업이 공간 또는 채널 차원을 통해 정보를 혼합한다는 의미이고, 이는 둘 다 혼합하지는 않는 Vision Transformer와 비슷한 특성이다.
depth wise convolution은 네트워크 FLOP와 정확도를 감소시키는데, 추가적으로 Swin-T와 채널을 맞추기 위해 채널 수를 64에서 96으로 증가시켜서 아래와 같은 결과를 냈다.
성능: 80.5%(1% up)
FLOPs: 5.3G (0.9G up)
Inverted Bottleneck

그림(a)는 기존 ResNet의 Bottleneck 구조이고, Mobilenet V2에서는 FLOPs를 줄이기 위해 그림(b)과 같은 Inverted Bottleneck을 사용하였다. Inverted Bottleneck을 채택한 이유는 Transformer 블록에서 MLP 블록의 hidden dimension에서도 input dimension의 4배나 넓은 inverted bottleneck 구조를 갖고 있기 때문이다.
결과적으로 downsampling residual block에 의해 많은 FLOPs가 감소되었으며 결과는 아래와 같다.
성능: 80.6% (0.1% up)
FLOPs: 4.6G (0.7 down)
Large kernel size

작은 커널 사이즈(3x3)의 컨벌루션 레이어를 쌓는 것이 표준처럼 자리잡고 있는데 이러한 작은 커널 크기는 현대 GPU에서 효율적인 하드웨어 구현을 가지고 있기 때문이다. 그렇지만 Swin-T는 윈도우 크기가 7x7로 3x3 크기보다는 훨씬 크기 때문에 large kernel 사이즈를 고려하게 된다.
여기서 (b)에서 (c)로 depthwise conv를 위로 올리게 된다. 이 과정은 복잡/비효율적인 모듈 (MSA, large-kernel conv)은 채널이 적을 것이고, 효율적이고 밀집된 1×1 레이어가 중요한 작업을 한다는 것을 의미한다. 그러나 이것만 변화시킨 경우 성능이 약간 감소한다.
이후 3, 5, 7, 9, 11 커널 사이즈를 비교하며 실험했을 때 7x7 커널 사이즈가 saturation 되었다.
성능: 79.9% → 80.6%
FLOPs: 유지
Micro Design
ReLU → GELU

- GELU는 ReLU의 부드러운 변형으로 생각 할 수 있으며 Google BERT나 최신 Transformer에서 사용되었다.
- 정확도는 변하지 않았지만 모든 activation function을 GELU로 사용하였다.
Fewer activation function

- 위의 그림에서 Transformer는 MLP 블록에 activation function이 하나만 있음. 그에 비해 ConvNet(conv → normal → activation)은 각 컨볼루션 레이어에 활성화 함수 추가
- ConvNeXt: 1x1 레이어 사이에 하나의 GELU만 남겨두고 나머지 activation function은 모두 제거
- 성능: 81.3%(0.7%상승) → 이때부터 Swin-T의 성능과 거의 맞먹는 결과를 얻음
Fewer normalization layer
- Transformer: MSA, MLP block 앞에서만 Normalization 수행
- ConvNeXt: 한 개의 batch norm(BN)을 inverted bottleneck의 첫 번째 1x1 conv layer 앞쪽에 적용시켰다
- 성능: 81.4%(0.1%상승) → Swin(81.3%) 넘음
BN → LN
- 그동안 비전 Task에서는 BN이 우선적으로 선택되는 반면 LN은 Transformer에서 사용되었는데 LN을 바로 ResNet에 적용하면 성능이 안 나오지만 modernize 된 ConvNeXt에서는 0.1% 성능 향상
- 성능: 81.5%
Separate downsampling layers
- 각 단계의 시작에서 residual block을 사용하여 3x3 conv 및 stride 2로 달성
- Swin Transformers에서는 단계 사이의 별도의 다운샘플링 층이 추가됨
- 그래서 공간 다운샘플링을 위해 2x2 conv 레이어를 사용
- 그런데 train이 발산하게 되고 공간 해상도가 변경되는 곳마다 정규화 층을 추가하는 것이 훈련을 안정화 할 수 있다.
- 각 다운샘플링 층 앞에 하나, stem 다음에 하나, 그리고 GAP 후에 하나 이렇게 LN을 넣어줌
- 성능: 82.0%
결론
ResNet을 Modernize하여 만든 ConvNeXt 모델은 Swin Transformer와 대략 동일한 FLOP, 파라미터수 처리량 및 메모리 사용량을 가졌음에도 불구하고 Shift Window Attention이나 relative position biases과 같은 특수한 모듈이 필요하진 않는다.
결과 비교

결과 비교를 해보자. 여기서 버블 크기는 FLOPs를 나타낸다.
그런데 한가지! 논문이 발표되고 나서 ViT논문을 낸 google brain에서는 Swin-T와 ConvNeXt는 데이터 augmentation을 매우 많이 한상태로 평가를 하였지만 자신들의 모델은 훨씬 적은 데이터로 통계를 냈다고 하여 이슈가 있었었다.
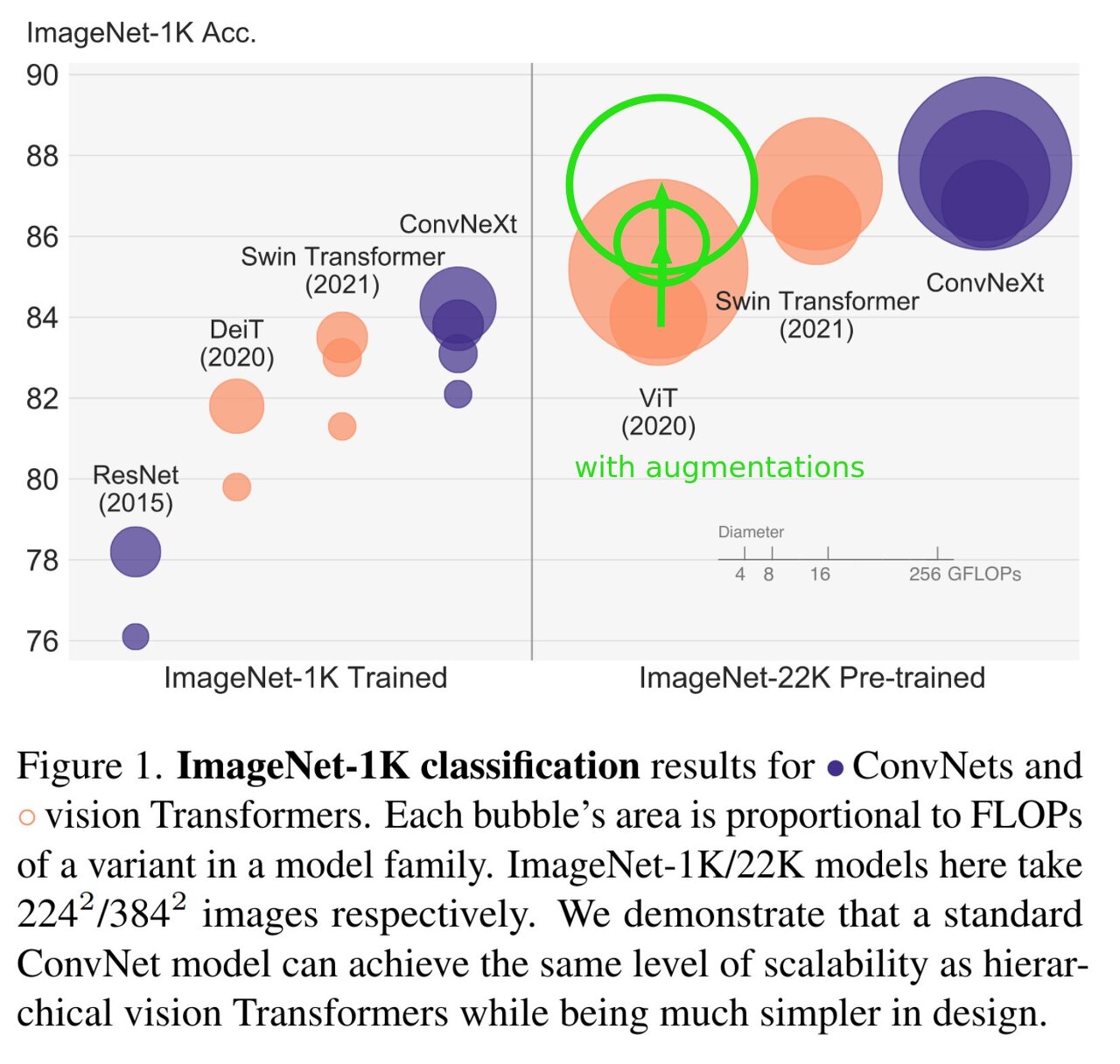
하지만 그럼에도 ConvNeXt가 더 좋은 성능을 낸다는 건 사실인 것 같다.

ImageNet-1K 데이터 셋으로 Swin-T를 파라미터와 FLOPs를 비슷하게 맞춰서 비교해 봤을 때 모두 성능이 좋았다. 그리고 FLOPs 뿐 아니라 throughput을 보았을 때도 더 좋은 것을 볼 수 있다. (ImageNet-22K 대용량의 데이터셋에서도 좋은 성능을 냄)

이미지 Task의 object detection 뿐아니라 segmention에서도 좋은 성능을 보였다.

그리고 이건 ConvNeXt를 일반적인 ViT와 같이 downsampling layer 없이 같은 패치 사이즈(ex 14x14)를 유지해서 결과를 본 것이다. 그럼에도 ConvNeXt가 여전히 성능이 좋았다는 것을 보여준다. FLOPs도 적고, throughput, training 메모리까지 좋은 결과를 보였다.
그래서 결론은,
Vision Transformer가 inductive bias가 적기 때문에 많은 양의 데이터를 넣었을 때 성능이 더 좋다고 흔히들 말했는데 잘 디자인된 ConvNet은 Vision Transformer보다 성능이 나쁘지 않고 큰 데이터 셋에서도 ConvNeXt도 충분히 성능이 좋다.
일반적으로 ConvNet에서 depthwise convolution을 사용하는 것은 속도도 느리고 메모리 사용량도 더 큰 것으로 알려져 있다. 그래서 ConvNext는 practically inefficient 하지 않을까 싶었지만! Inference throughput에서 보면 Swin Transformer보다 견줄만한 좋은 성능을 보인다는 것을 알 수 있었다.
이 논문의 저자가 결국 말하고자 하는 것은 여기서 효과적인 것은 Vision Transformer의 self attention 매커니즘에서 비롯된 것이 아니라 ConvNet의 inductive bias에서 나온 것이라는 것이다.
마치며
- 기존에 알려져있던 Vision Transformer는 inductive bias가 낮기 때문에 대량의 데이터에서 CNN 기반의 모델보다 더 높은 성능을 갖고 있다고 알려져 있다.
- ConvNeXt는 기존에 많이 쓰이는 것들을 modernize 하여 새롭게 디자인했고 그 결과 비전의 다양한 task에서 transformer기반의 모델보다 더 좋은 성능을 보여주었다.
- 그래서 저자는 사람들에게 기전에 널리 알려진 시각에 대해서 챌린지를 던지며 vision 분야에서 convolution의 중요성에 대해서 다시 한번 상기시키고자 하였다.
Reference
https://medium.com/@atakanerdogan305/convnext-next-generation-of-convolutional-networks-325607a08c46
https://blog.kubwa.co.kr/논문리뷰-a-convnet-for-the-2020s-9b45ac666d04
https://www.youtube.com/watch?v=Mw7IhO2uBGc



