
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- CASE WHEN
- 백엔드
- recall
- 결정트리
- sorted
- 오차 행렬
- Batch Normalization
- DecisionTree
- ifnull
- 재현율
- beautifulsoup
- 빠르게 실패하기
- 정밀도
- 감정은 습관이다
- LAG
- 지도학습
- 웹서비스 기획
- NVL
- 비지도학습
- NULLIF
- 데이터 프로젝트
- 데이터 전처리
- SQL
- Normalization
- 강화학습
- five lines challenge
- nvl2
- 평가 지표
- layer normalization
- 데이터 분석
- Today
- Total
Day to_day
Batch Normalization, Layer Normalization 비교 본문
들어가며
Batch Normalization은 익히 들어 잘 알고 있었지만 Layer Normalization과 비교해서 개념적으로 어떻게 다른지, 그리고 왜 사용하는지에 대해서 깊게 생각해 본 적이 없는 것 같다. 그래서 먼저 Normalization에 대해 알아보고, Batch Normalization과 Layer Normalization에 대해 알아볼 것이다.
Normalization
입력 데이터의 분포를 조정하거나 표준화하여 학습의 성능을 향상시키는 기술이다.
예를 들어 정규화 방법 중 하나인 데이터 표준화(Standardization)는 데이터를 평균과 표준 편차를 이용하여 정규 분포를 만들 수 있다.
그것을 식으로 나타내보자.
$$ \hat{x}^{(k)}= \frac {x^{(k)}-E[x^{(k)}]}{\sqrt{Var[x^{(k)}]}} $$
- 원본 데이터 x를 x^으로 변경할 때, 모든 x의 평균을 뺀 뒤에 모든 x에 대한 표준 편차로 나눠 주면 된다.
- 모델 내부에서 정규화 기법을 사용해야되는 이유에 대해 직관적으로 이해해보려고 한다.
예를 들어 입력의 특징이 서로 다른 범위에 있을 때 어떻게 될지 생각해 보겠다. 하나의 입력 특징은 [0,1]의 범위에 있고, 다른 하나는 [0,100000] 범위에 있다고 하자. 그러면 모델은 첫 번째 특징은 다른 범위에 비해 너무 작은 분포를 갖고 있기 때문에 단순히 무시하게 될 것이다. - 그러면 입력 데이터를 정규 분포로 만들어주는 것이 왜 중요한가. Input layer에서 skew가 심한 분포의 형태로 들어오게 되면 activation function을 지날 때 sigmoid같은 함수의 경우 많은 값이 0으로 수렴하게 되어서 gradient vanishing 문제가 일어난다. 이 문제를 Internal Covariate Shift라고 한다.
Internal Covariate Shift
Convariance Shift가 hidden layer안에서 일어나는 현상. 이전 layer에서 정규 분포를 따르더라도 hidden layer와 activation function을 지나고 나면 다른 분포를 갖게 되어 가중치 업데이트가 잘 일어나지 않는다.
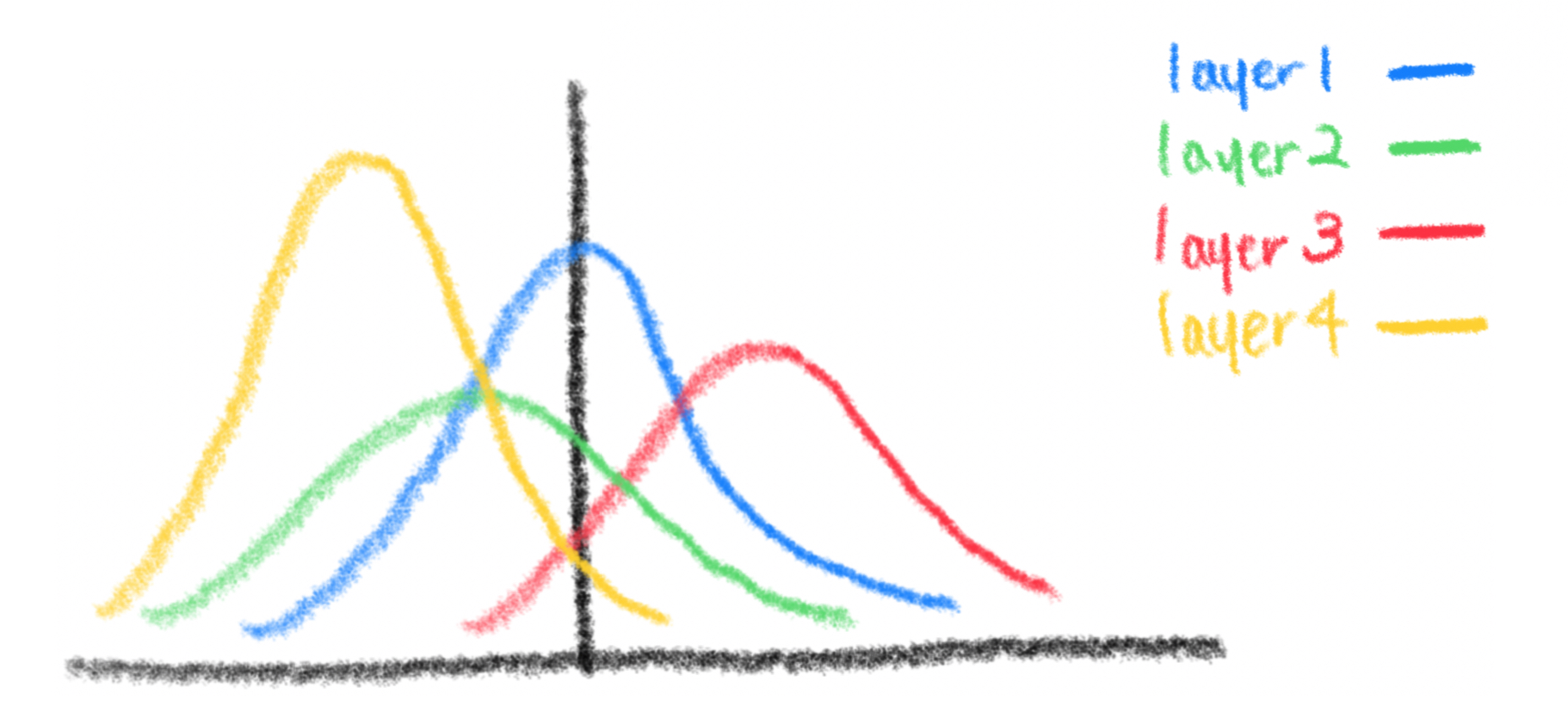
처음 layer1에서는 정규 분포를 따르더라도 layer2 → layer3 → layer4를 거치면서 계속 데이터가 치우치는 현상이 발생한다. 그렇게 되면 학습에 그리 효과적이지 못한다.
다시 정리하자면,
처음 입력에서 정규 분포로 만들어도 hidden layer를 지나면서 계속 정규 분포를 벗어나더라 → Internal Covariate Shift
Batch Normalization
그래서 분포를 매 layer마다 정규 분포로 만들어주기 위해 배치 normalization를 도입하기 시작했다.
자 그럼 batch normalization이 왜 필요한지를 먼저 알아보자.
예를 들어 하나의 배치에 100개의 데이터가 있다고 하자. 그러면 각각의 배치에 속해있는 데이터를 activation function에 넘겨줄텐데 여기서는 sigmoid function을 쓴다고 가정하자.
그런데 여기서 입력 데이터를 sigmoid에 넣었더니 값이 매우 커서 activation function을 지나면 0에 가깝게 수렴할 것 같다고 하자. 그러면 back propagation이 잘 일어날까? 값이 0만 계속 반환되는데? 잘 안될 것이다. 그래서 batch normalization을 이용해 우리가 적당한 곳(학습이 잘되는 분포)에 데이터를 흩뿌려주자는 것이다.

그러면 분포를 아래와 같이 바꾸면 어떨까? 데이터가 분포한 곳을 보니 거의 선형함수에 분포시킨거나 다름없다. 우리가 비선형성 activation function을 쓰는 의미가 없을 것이다. 그래서 잘 학습할 수 있도록 골고루 조절해보는 것이 핵심이다.

Batch Normalization 수식

그러면 단순히 평균 0에 표준편차 1의 분포가 가장 학습하기 좋은 분포냐? 당연히 아닐 것이다.
미니 배치마다 평균, 분산을 구해서 normalize를 진행한다. 그런 다음 activation과 데이터의 특성마다 학습에 효과적인 적절한 분포가 있기 때문에 감마와 베타를 학습을 통해 알아낸다.
- 감마와 베타는 학습가능한 파라미터로 감마를 통해서 스케일링 효과를, 베타를 통해서 shift 효과를 낼 수 있다.
- 이것을 통해 어떤 분포가 가장 학습에 효과적인 분포인지를 back propagation을 하며 스스로 알아내게끔 하는 것이다.
Batch Normalization - 추론하기
그러면 추론을 할때는 어떻게 batch normalization을 적용할까?
- 추론(Inference)할 때는 데이터가 하나씩 들어오는데(batch가 1개라는 말) 평균을 어떻게 구하고 표준편차는 어떻게 구해서 적용하지?
- 그래서 batch별로 평균과 분산을 구할 수 없기에 학습할 때 구해둔 배치별 평균과 분산을 재사용한다. batch마다 평균과 분산을 모두 저장하는 게 아니라 이동 평균을 이용해 처음에 산출된 평균의 가중치는 낮추고 최근에 산출된 평균에 좀 더 비중을 두어 batch normalization을 한다.
모집단 추정 식은 아래와 같다.

그렇게 구한 평균과 분산을 이용하여 inference에서 batch normalization을 한다.

Batch normalization의 장점
- 수렴 속도가 빠르다. 일단 learning rate를 크게 사용해도 되기 때문에 빠르기도 하다.
- learning rate를 크게 가져가도 된다.
- regularization 역할도 한다. 기존 정규화를 위해 쓰인 L1, L2 regularization이나 dropout을 생략해도 효과가 있었다는 연구도 있다.
Layer Normalization
그런데 sequence data의 경우 instance크기가 모두 다르다.(글의 길이가 다르기 때문)
또한 time step별로 통계량을 이용하기 어려워 RNN에서는 사용하기 어렵다. 이 문제를 해결하기 위해 각 배치에 있는 모든 feature들의 평균과 분산을 구해 normalization 한다는 것이 layer normalization이다.
각 hidden node의 feature별 평균과 분산이 아니라, hidden layer별로 계산을 하는 것이다.
그래서 평균과 분산은 배치와 독립적이며 이 레이어는 NLP분야의 RNN의 hidden layer에서 많이 쓰인다. 아래의 수식은 Batch normalization과 Layer normalization을 비교한 식이다.


참고) Layer normalization를 코드로 구현해 보는 방법
Batch Normalization vs Layer Normalization

Batch normalization과 layer normalization을 비교하는 사진으로 위의 사진이 자주 나오던데 사실 나는 정확하게 이해하긴 어려워서 다른 사진을 찾아왔다!
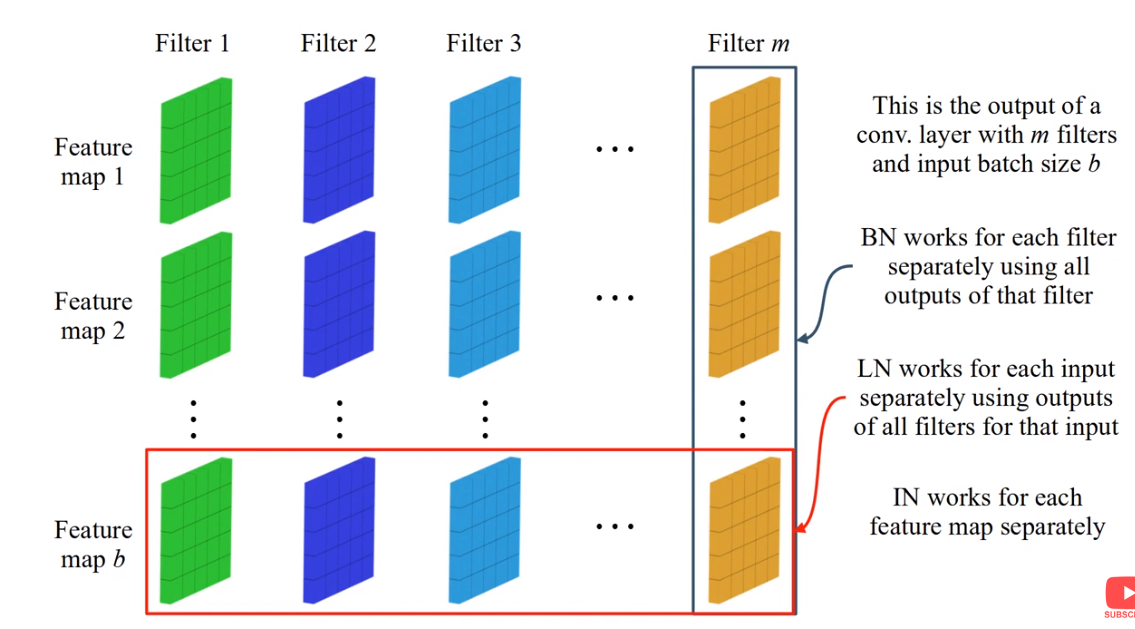
하나의 이미지를 input으로 두고, activation function을 지난 후 각각의 filter를 지난 feature map이 위와 같이 있을 때의 상황이다.
batch normalization은 각각의 filter의 평균과 표준편차를 구하는 것이다. 그러니까 처음 사진에서는 파란색 화살표 가로축으로 계산하는데 그게 filter 별로 구하는 것이다.
반면 layer normalization의 경우는 데이터 샘플에 대해서 normalization을 하는 것이다.
마지막 정리!
- feature 단위로 정규화를 할 것인가 - batch normalization
- 데이터 샘플 단위로 정규화를 할 것인가 - layer normalization
- 처음 그림에서 Batch Normalization에서는 feature가 6개이므로 평균과 표준편차가 6개 나옴 (feature 수에 맞게)
- Layer Normalization은 데이터 샘플 단위로 평균과 표준편차를 계산해서 정규화 실행 (feature에 상관없이 데이터 샘플 수가 3개면 3개의 평균과 표준편차가 나옴)
여러 normalization 기법

Instance normalization


Batch Normalization, Layer normalization 외에도 다양한 Normalization 방법이 있다.
그 중 하나로는 Instance Normalization으로 한 개의 배치 내에 각 채널마다 평균과 분산을 구해 normalization 하는 것이다.
보통 CNN segmentation, Real time generation, Style transfer에서 사용된다.
Instance Normalization은 각 개별 샘플의 스타일을 목표 스타일(γ와 β로 모델링됨)로 정규화할 수 있다. 이러한 이유로 특정 스타일로 전이하는 모델을 훈련하는 것이 더 쉽다. 왜냐하면 네트워크의 나머지 부분은 콘텐츠 조작과 지역적 세부 사항에 대한 학습을 집중할 수 있으면서도 원래의 전역 정보(즉, 스타일 정보)를 버릴 수 있기 때문이다.
Group normalization

채널 축을 따라 그룹 단위로 normalization된다. (그룹이 하나라면 layer norm, 전체라면 batch norm이라고 할 수 있다)
주로 컴퓨터 비전 분야에서 많이 쓰이며 group normalization은 배치마다 평균과 분산을 저장할 필요가 없으므로 메모리 사용량을 줄일 수 있다.
마치며
더 자세하게 알고싶은 사람은 아래의 논문을 참고하여 공부하면 좋을 것 같다!
Reference
https://deepinsight.tistory.com/116 https://cvml.tistory.com/5
https://theaisummer.com/normalization/
https://3months.tistory.com/480
'Deep Learning' 카테고리의 다른 글
| VGGNet 아직도 정리 못했다면 빠르게 핵심만! (0) | 2024.04.01 |
|---|---|
| CBOW & Skip gram 개념 완벽 이해하기!! (0) | 2024.03.26 |
| 1 x 1 convolution이란? 직관적으로 이해해보기 (0) | 2024.02.25 |
| Global Average Pooling이 뭐길래? (1) | 2024.02.24 |
| Knowledge Distillation 이해하기 (0) | 2024.02.03 |



