
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 강화학습
- 정밀도
- Normalization
- five lines challenge
- DecisionTree
- 데이터 분석
- layer normalization
- 지도학습
- 웹서비스 기획
- 결정트리
- 오차 행렬
- recall
- LAG
- NVL
- nvl2
- 빠르게 실패하기
- 데이터 전처리
- 비지도학습
- beautifulsoup
- SQL
- 데이터 프로젝트
- 재현율
- sorted
- ifnull
- Batch Normalization
- NULLIF
- 백엔드
- 평가 지표
- 감정은 습관이다
- CASE WHEN
- Today
- Total
Day to_day
VGGNet 아직도 정리 못했다면 빠르게 핵심만! 본문
들어가며
너무나도 유명한 VGGNet을 읽어보면서 짧게 정리하고 넘어가는 포스팅을 작성하려고 한다. 이 글을 읽기 전에 컨볼루션 layer이 기본적으로 어떻게 동작하는지, pooling, stride, padding에 대한 개념을 알고 VGGNet을 읽어보는 것이 좋을 것 같다.
VGGNet
이 연구에서 강조하는 점은 대규모 이미지 인식 환경에서 합성곱 신경망의 깊이가 정확도에 미치는 영향이다.
특히 VGGNet에서는 작은 컨볼루션 필터(3x3)를 사용하여 깊이를 증가시킨 모델이다.
VGGNet은 옥스포드 대학의 연구팀 VGG에 의해 개발된 모델로써, 2014년 ImageNet 이미지 인식 대회에서 준우승을 했다. 특히 이 모델은 2013년 8개의 layer에 불과했던 ZFNet 모델에 비해 16, 19개의 layer로 굉장히 깊어지면서 에러율을 확연히 낮췄다.

VGG Net 구조
- VGG Net은 ConvNet 아키텍처의 중요한 측면인 깊이에 대해서 다루며 이를 위해 아키텍처의 다른 매개변수는 고정하고, 컨볼루션 레이어를 추가하여 네트워크의 깊이를 증가시켰다.
- 그리고 모든 레이어에서 작은 컨볼루션 필터 (3x3)를 사용하기 때문에 더 깊고 정확한 ConvNet 아키텍처를 제시했다.
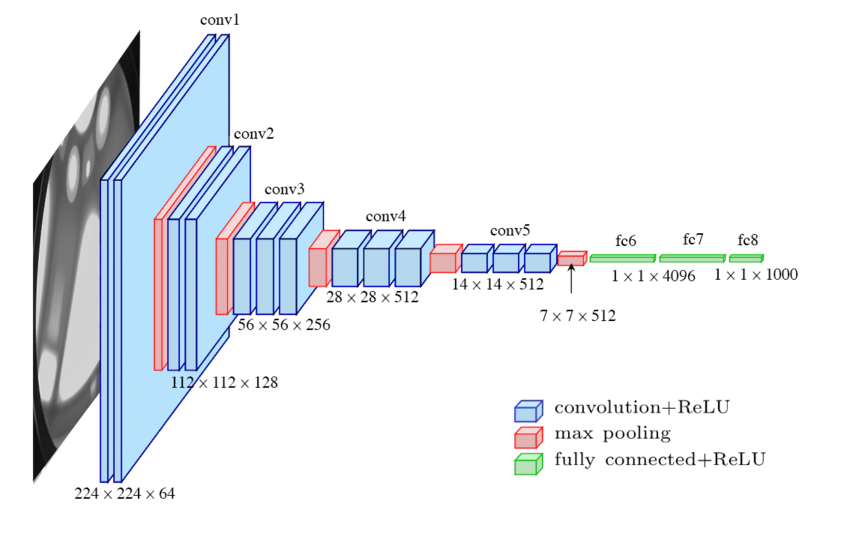

- Input layer에는 224x224x3 RGB 이미지가 들어간다.
- 컨볼루션 레이어 입력의 공간 패딩은 컨볼루션 후에 공간 해상도가 보존되도록 하기 위해 설정된다. 즉, 3x3 컨볼루션 레이어의 패딩은 1로 두었다.
- 일부의 컨볼루션 레이어 뒤에 max pooling layer가 수행되며, 2x2 픽셀 window, stride 2로 해서 stamp 찍듯이 값을 계산한다. 그래서 max pooling 다 레이어를 보면 해상도가 반으로 줄어든 것을 볼 수 있다.
- 마지막으로는 Fully Connected layer가 이어지는데, 첫 번째와 두 번째 층은 각각 4096개의 노드를 가지고 있으며, 세 번째 층은 1000개의 노드를 가지고 있어서 총 1000개의 클래스에 대한 분류를 담당한다.
- 또한 모든 hidden layer에는 ReLU activation function을 가지고 비선형성을 적용한다.
작은 사이즈의 컨볼루션 필터로 네트워크를 깊게 쌓는 것이 왜 중요할까?
작은 사이즈의 컨볼루션 필터를 쌓는 것은 두 가지 이점이 있다.
- 줄어든 연산량
아래의 예시를 보면, 5x5의 영역을 보기 위해 3x3으로 두 번 보거나 5x5로 한번 보는 경우가 있다.
두 경우 계산차이를 비교해보면 3x3x2=18, 5x5=25로 3x3을 두번 통과하는 것이 더 적은 파라미터 수로 layer를 통과하면서 비선형성을 준다고 할 수 있다. - Receptive field
합성곱 신경망(CNN)에서 각 뉴런이 입력 이미지에서 정보를 수집하는 영역을 Receptive field라고 한다.
아래의 예시를 보면서 설명하자면, 두 번째 layer에서 이전 layer의 5x5를 보는 데에는 3x3 filter로 충분하고 그 두 번째 3x3 영역을 보는 데는 세 번째 layer에서 1x1로 볼 수 있다. 그래서 이 layer의 receptive filed는 5x5라고 할 수 있다.
특히나 CNN에서는 이 receptive field를 충분히 가져가서 놓치는 부분이 없도록 해야한다. 그래서 결국 마지막 layer는 결국 5x5의 receptive field를 갖고 있기 때문에 3x3 filter를 두 번 사용한다 해도 5x5 영역을 모두 볼 수 있다는 것이 확인됐다.

마지막에 있는 Feature map은 어떤 의미를 가질까?
MLP 레이어는 VGGNet에서 80%의 연산량을 담당할 정도로 Fully Connected Layer이기 때문에 파라미터 수가 굉장히 많다. 그러면 MLP가 갖는 의미는 뭘까?
그 이전에 ConvNet이 갖는 특징을 보자.
ConvNet은 입력 데이터인 이미지의 위치 정보도 갖고 있다는 특징이 있다. 주변 픽셀과 연산을 하기 때문에 위치 정보가 들어가는 것이고, 만약 처음부터 냅다 FC를 그냥 통과시키면 픽셀의 위치는 상관없이 픽셀간의 연산을 해버리기 때문에 이미지 분야에서 위치 정보를 활용하지 못하게 되는 것이다.
그래서 직관적으로 생각해보면 위치적으로 가까운 픽셀끼리 먼저 조합해 보고(Convolution Layer), 그다음 layer에서 조합된 정보를 가지고 좀 더 멀리 떨어진 정보도 함께 보는 것(MLP)이다.
그래서 결국 마지막에 있는 feature map은 각 영역의 특징을 가지고 있는 것이고 MLP 레이어를 거치며 정제된 특징을 싹 다 본다고 이해할 수 있다.

위의 예시와 같이 CNN의 각 레이어는 입력 이미지의 다양한 특징을 추출한다. 일반적으로 CNN은 점진적으로 추상화된 특징을 학습하도록 설계되어 있는데 이는 네트워크의 초기 레이어가 단순하고 지역적인 특징을 학습하고, 더 깊은 레이어로 갈수록 보다 복잡하고 추상적인 특징을 학습한다는 것을 의미한다.
- 저수준 특징: 네트워크의 초기 레이어는 이미지의 저수준 특징을 보는 경향이 있다. 이러한 특징은 선, 모서리, 색상 변화 등과 같이 이미지의 지역적인 세부 사항을 주로 작은 커널 크기를 가진 컨볼루션 필터를 통해 추출한다.
- 중간 수준 특징: 네트워크의 중간 레이어는 저수준 특징을 결합하여 더 복잡한 패턴을 학습한다. 예를 들어 텍스처, 간단한 패턴 또는 물체 부분과 같은 것들을 나타낼 수 있다.
- 고수준 특징: 더 깊은 레이어는 고수준의 추상적인 특징을 학습하며 주로 물체의 종류, 클래스 또는 물체의 관계와 같은 것들을 포함한다. 예를 들어, 인간 얼굴, 자동차, 강아지와 같은 객체를 인식하는 데 사용될 수 있다.
마치며
VGGNet을 코드 구현하는 것도 추가해야겠다. 조만간..ㅎ
다음 논문은 ResNet 빠르게 핵심만! 으로 다시 정리해서 와야겠다
'Deep Learning' 카테고리의 다른 글
| ResNet 핵심만 빠르게! (0) | 2024.04.29 |
|---|---|
| GoogleNet (InceptionNet) 빠르게 핵심만! (0) | 2024.04.22 |
| CBOW & Skip gram 개념 완벽 이해하기!! (0) | 2024.03.26 |
| Batch Normalization, Layer Normalization 비교 (5) | 2024.03.16 |
| 1 x 1 convolution이란? 직관적으로 이해해보기 (0) | 2024.02.25 |



